Use `varchar`, not `text`
If you started your programming journey in the early 2010s like I did, then it’s likely that the first relational database you ever learned to use was something other than PostreSQL. While PostgreSQL today enjoys its position as developers’ preferred database technology, this hasn’t always been the case. MySQL was—and is—an immensely popular database option. A lot of people first learned SQL using MySQL, and I am one of those people.
If you’re in the same boat as me, then PostgreSQL’s text data type was a revelation to you. Unlike in MySQL—where the varchar and text types have very different performance characteristics—the PostgreSQL text type is functionally identical to the PostgreSQL varchar. This is a wonderful thing to learn, and my very first thought was that I would be freed from the drudgery of micromanaging column length limits. No more worrying about whether something should be varchar(32) or varchar(64)—just make it a text column and move on with your life.
Since encountering PostgreSQL and falling in love with the text type, however, my opinion on it has shifted. While I still think that the text type can be useful in some situations, I believe that varchar should be the default type you reach for when storing text data.
Why? Because in PostgreSQL the text type is effectively boundless. Any text column is immediately capable of storing up to 1 GB of data per row, and the odds are really good that you have at least one API endpoint that accepts arbitrarily long strings. That’s bad news. You should never—under any circumstances—promise unlimited anything to your API consumers or product customers.
APIs that scale are designed with carefully considered constraints in place to limit scaling factors. If your API supports writing an unbounded string to your database, then it is only a matter of time before someone starts storing 100 MB JSON blobs inside their first name. There’s nothing you can do about this. Hyrum’s Law is absolute and all-encompassing.
Users don’t have to be malicious
I’m not even talking about this from a cybersecurity perspective. While a would-be attacker intentionally DDoSing you with large string values is a valid concern, unbounded string lengths can be problematic even in cases where your consumers have good intentions.
AWS APIs, Stripe, and many, many other services all allow you to attach arbitrary key-value metadata to resources. This capability is tremendously useful for third-party developers as it allows them to collocate important details with their associated API resources. So long as those third-party developers are OK with trusting their data to you, they benefit from reduced bookkeeping.
Consider the case where you have a table of orders and you want to correlate Stripe payments to that order. In theory adding a single stripe_payment_id to your order table is simple enough, but the real world is more complicated. It could be possible for a customer to pay for their order across multiple different payments.
So now you’d need to maintain a many-to-one mapping of payment IDs to orders. Still not the end of the world, but CRUDing these rows involves more moving parts than managing a single column. Even after you have stored this data, you still need to perform API lookups from Stripe to actually load the payment resources.
With metadata it is possible to directly search Stripe for payments which match your specified metadata filters. Zero bookkeeping to do on your end—other than sending the metadata to Stripe in the first place—and you can get all the data you need with one atomic API call. It’s very convenient.
The problem with an unbounded text field is it means I can use the title of a Trello card, my profile’s bio text, or anything else as a form of “unofficial” metadata storage. I don’t need to have bad intentions as a consumer of your API in order to cause some real problems for you.
Storage isn’t an issue, but CPU and networks are
Back when I was studying at University of Waikato, I worked with Professor David Bainbridge on some OCR functionality for the Greenstone digital library software. On one afternoon Bainbridge reflected on the late Ian H Witten’s “Managing Gigabytes” book.
Witten’s contributions to the field of data compression were significant. Managing Gigabytes, in fact, gave Sergey Brin and Larry Page the tools they needed to go on to found Google.
It was curious—Bainbridge thought—that so much of the history of computer science in working around resource limitations that no longer exist. When “Managing Gigabytes” was written back in 1994, a 500 MB hard drive was considered pretty good. These days we don’t blink an eye at the idea of a video file weighing in at a few gigabytes.
Storage is pretty cheap and ubiquitous these days. If the only salient factor here were storage, then text would be perfectly fine to use everywhere.
But the other resources are an issue. The default request payload limit for AWS API Gateway is 10 MB, and that is a tremendously large request payload for most APis. My experience tells me that a typical average is far closer to the 1 KB mark, which is ~10,000x smaller.
If you’re running on medium EC2 instances you get 4 GB of memory to play with. Some of that will get eaten up by fixed overheads like your operating system or language runtime, so in practice you might only have enough memory available to hold on to 360 different 10 MB requests.
Tinker with Little’s Law for a bit, and you’ll see it doesn’t take a particularly high requests/second figure to start getting OOM killed. It also doesn’t take very many of these multi-megabyte text fields to start seriously weighing down your network links—especially in cases where your API endpoint is returning a list of resources.
How to pick good string limits
Back when I was first learning to use SQL, the tutorials I followed placed a lot of emphasis on picking “optimal” varchar length limits in the name of performance and disk space. While performance is still a valid concern, the disk space argument doesn’t hold too much weight these days.
And even in the case of performance the issues only really start to become an issue when the data we’re working with is pathologically large. There’s virtually zero difference between processing a string that’s 80 characters long instead of one that’s 64 characters long. It’s when you start blowing lengths out by a couple orders of magnitude that the problems start cropping up.
So the goal here isn’t to micro-optimize your schema. It’s just to put sane and sensible limitations in place to prevent API consumers from inadvertently burdening your system. If you overshoot your maximum length then that’s OK—and in PostgreSQL, there’s no penalty for underutilization of a varchar column anyway.
My recommendation here is to think about your maximum string lengths in terms of orders of magnitude. Just pick a base length for a “tiny” string, and then add one order of magnitude for each string length description.
I like to pick 50 as my base length. That means a “tiny” string gets 50 characters, and then one step up a “small” string gets 500 characters. I like this scale purely because 500 is pretty close to 512, and as a software engineer I am naturally drawn to powers of 2. They just feel right.
A base length of 50 also happens to result in some fairly liberal maximum string lengths, which is what we actually want. At the end of the day, we’re only looking to filter out things which are very clearly and obviously wrong. We still want to be able to accept anything that remotely resembles a legitimate value. Again, overshooting is fine.
Here’s a taxonomy of string lengths I think in terms of, and for each string length I’ve given an example of where it might be used within the context of a blog:
- Tiny strings (think: post tags) — 50 characters
- Short strings (think: names) — 500 characters
- Medium strings (think: bio text) — 5,000 characters
- Long strings (think: blog post) — 50,000 characters
These limits are by no means a hard and fast recommendation. You may choose to use a different base length, or you may decide to scale up your string length tiers using a different methodology than naïvely adding an order of magnitude at each step. This is just what I tend to use myself.
Encoding these types into the database layer doesn’t mean you can’t also encode them elsewhere. A lot of applications aren’t able to gracefully transform database errors into human-friendly error messages on a frontend, so including some explicit validation at the edge of your API layer can still be valuable.
Likewise, if you ship an API specification you will likely want to include your string length constraints there as well. OpenAPI supports a maxLength modifier which lets you do exactly this.
Why not just use a check constraint?
If you’re a long-time reader of this blog then you’ll know that I’m a big fan of documentation. I think it is very hard to scale an engineering team—either in terms of headcount or code surface area—in the absence of high quality documentation. Past a certain point the business context and the codebase become too complicated to fit inside your head, and at that point you can do one of two things:
- Continuously relearn how the codebase works from first principles
- Use to documentation to answer your questions immediately
If the available documentation is poor then you are forced into doing (1), but it is an extremely disadvantageous position to be in. It is truly painful to work in such an environment.
While you could combine a text column with a check constraint in order to enforce length limits, I don’t like this model because it is less discoverable—and therefore less self-documenting—than using varchar.
When I view the contents of a table in any SQL database browser, I will be able to clearly see what type each column has. If a column has been modeled as varchar(500), then I don’t need to go digging to find that information because it’s right there on my screen.
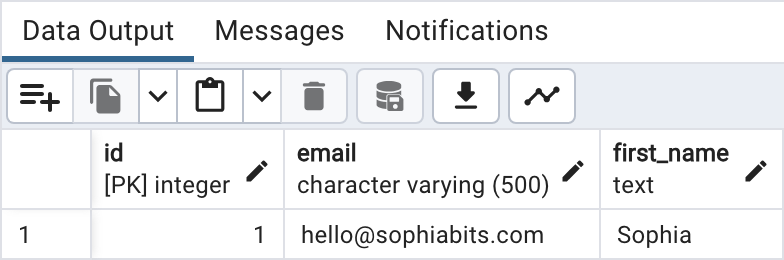
Constraints, on the other hand, tend to not be displayed front and center by database viewers. When I look at a database table containing text columns I only get to see the text type. To figure out whether or not there’s a length limit at play, I need to dig in to the table’s constraints and manually inspect them.
Not the end of the world on its own, but a thousand paper cuts like this over the course of the day add up. Even on an individual level losing a few seconds here and there can be a big productivity drag. Multiply that by the size of your team and you have the makings of a real velocity problem on your hands.
A lot of teams self-sabotage their delivery because they just don’t care about small details like this. Unfortunately, it turns out that small details matter They compound over time and your team accumulates damage for it.
So I don’t like using check constraints for the same reason I don’t like using UUIDs. There are clearer, less obscure solutions available and I’m a strong believer in the value of making things extremely explicit. Programming is hard enough as it is—it’s better to be kind to our future selves.
Final thoughts
Constraining maximum string lengths is a small piece of a much broader story about resilience in software engineering. Implementing these constraints are unlikely to completely solve all of your scaling and integrity issues, but doing so does give you another protective layer of cheese against misuse of your API.