LLMs are just tools
I manage and run Crimson’s engineering all hands, a biweekly meeting where someone from the engineering organization will either talk about something they’re passionate about, or run a training session. These meetings are a really valuable way to build community and provide ongoing professional development.
At last week's all hands I presented on LLMs, and while I can’t share the slide deck—it includes some confidential information—I think the contents are worth translating into a blog post.
There’s a lot of discussion going on around the world about LLMs like GPT. GPT is an amazingly useful tool which largely commoditizes English language NLP, and there are both well-founded fears and hopes about what this technology means for us as a species. The results you can get from a little bit of prompt engineering are nothing short of incredible; in fact, they would have been unimaginable even a few years ago.
It wasn’t at all obvious that transformers could scale to this extent. Sure, older models like BERT were decently large, but they pale in comparison to the scale of the newest GPT models. We’re talking multiple orders of magnitude of additional size. OpenAI made a big and expensive bet, and it’s paid off.
We’re in the middle of a gold rush now where nearly every company on the planet is trying to stuff LLM technology into every product imaginable. We are going to—and are already—see a substantial amount of innovation happen over the next couple of years.
At the same time, though, it’s incumbent on us as software professionals to remain pragmatic and not get swept up by the current zeitgeist. GPT and other LLMs may be very useful tools, but they’re not silver bullets.
Neural networks
In the seminal “Attention is all you need” paper, a group of researchers from Google described the transformer architecture. Since the publishing of that paper, transformers have become the state of the art architecture for virtually all natural language processing problems.
How did transformers come to be so dominant? It’s worth looking at some of the other neural network architectures and analyze their limitations.
A quick refresher
Neural networks tend to operate on matrixes. The input to the network will be a matrix, and each neuron in the network will have a “weight” matrix which gets multiplied against the input. After this multiplication occurs, an “activation function” is applied to introduce nonlinearity to the system. The weight matrixes are commonly referred to as “parameters.” These weights are what the neural network is ultimately trying to learn.
One of the earliest neural network architectures was the convolutional neural network, known as a “CNN.” CNNs were inspired by the human eye, and are widely used today for image processing tasks. CNNs work by taking in an input and progressing it through each layer of the architecture, ultimately producing a result in the final “output” neurons.
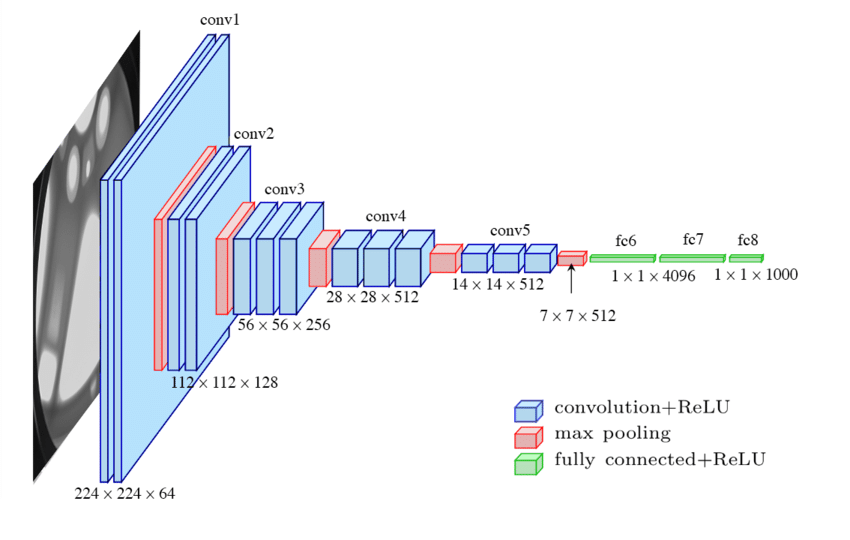
Source: "Automatic localization of casting defects with convolutional neural networks"
The input image is converted to a vector for processing, and each layer of the network progressively reduces the image down until you are finally left with an output. The output in this case could range from whether the image contains offensive content all the way through to what action a self-driving car should take. Images are easy to turn into vectors because pixel data is already numeric, unlike human language.
Convolutions work well, but they’re not suitable for all tasks. They’re really good for data with high locality—images being the most obvious example. Two pixels next to each other in an image are far more likely to be related to each other than pixels far away from each other. While human languages do exhibit this to an extent, language is an overwhelmingly sequential kind of data. Words occurring earlier in the sequence have an impact on words occurring later on, as they provide context.
Any problem involving sequential data is a poor match for a CNN, because the architecture doesn’t “remember” anything about its previous input. It’s a stateless architecture which takes in an input and spits out an output. While a perfect approach for tasks like image classification, it's easy to see how this architecture might underperform on natural language processing tasks.
Recurrent neural networks (RNNs) solve this problem by adding in a form of memory to the system. The most common approach leverages a “long short-term memory” (LSTM) cell, which you can see an example of below.

Source: Wikimedia Commons
At a high level LSTM cells add a hidden state parameter, h, which gets combined with the model's input c to produce the final output. The final output can be consumed by the system calling the model, and internally the final output is then multiplied by a weight to produce the next h value. In this way, LSTMs are able to “remember” some aspect of their previous execution.
LSTMs have a few more pieces in practice—a “forget” gate allows for clearing out the value of h, and a “remember” gate allows for determining whether an output should be “remembered” in the first place.
The addition of state to the architecture means that RNNs are well-suited for language processing tasks. For a long time they were the state of the art, but they suffer from two big limitations:
- Vanishing/exploding gradients. This is a problem for all architectures discussed so far. Anything which learns through a gradient-based method (RNNs) or backpropagation (CNNs) is vulnerable to these problems. This limits the effectiveness of RNNs on long sequences of text.
- Unable to parallelize. RNNs train on sequences one element at a time, and it’s difficult to parallelize this activity. It's impossible to know the value of
hwithout first calculating the previous value ofh. This ultimately means that the scale of an RNN model is limited, as you run into the limits of vertical scaling very quickly.
The transformer architecture solves both of these problems.
The transformer
The transformer architecture introduces a number of innovations compared to the RNN. The first major departure is that they aren’t sequential: transformers operate on complete sequences (e.g. sentences) at once rather than individual elements in the sequence (e.g. words).
This is done by dispensing of that linear h state. As any value of h is dependent upon all previous values of h—and therefore, dependent on executing the model at each step in the sequence—it is a requirement to find a different architecture. Transformers use an “attention” mechanism to compute the relative importance of each token in the input sequence, and generate “positional encodings” to encapsulate the order of each token in the sequence.
This, it turns out, is enough to do some really interesting language processing. Word vector embeddings alongside the positional encodings are fed through a series of encoders, the output of which can be fed into a series of decoders.
Decoders produce a sequence of output words alongside a probability for each word, and this can be used to build features like Google Drive’s smart compose. Each encoder and decoder has an attention unit, and each pair can be run in parallel to other encoder/decoder pairs enabling scale.
The transformer architecture, in brief, is very good at determining what the next word in a sentence should be. Asking the transformer to repeatedly answer that question lets you automatically generate documents.
This is what GPT and friends are doing under the hood.
LLMs are transformers
At their core, LLMs are simply massively scaled-up transformer architectures. OpenAI layer on a few additional processes—most notably content moderation—but the limitations of GPT and other LLMs are the same as any other transformer-based system.
Transformers are really bad at uncovering novel information. Unlike a machine learning model that’s been specifically trained to predict future stock prices, transformers are constrained by the text used to train them. Their functionality is to produce the most likely next token given the start of a token sequence—almost by definition, novel ideas are not going to be the most likely text completion.
If you think you’ve seen something novel come out of ChatGPT then it may very well have been novel to you, but somewhere out there in the Common Crawl dataset (this dataset makes up the majority of GPT’s training data) you’ll be able to find the original description of that idea.
They’re also constrained by their training data, and the GPT models have not been trained on your proprietary datasets. While the GPT models do exhibit an incredible ability to learn tasks in-context, the token limits at play mean that the context you can provide to the model is limited. I doubt Netflix will replace their in-house recommender system with something based on an LLM any time soon.
But if you understand how the technology works at a more fundamental level, it becomes clear that GPT is not—and won’t become—AGI in its current form. This scaled up transformer architecture seems to capture some part of our human ability to reason, but it’s not a complete replacement for the human brain.
I think it’s a little unfair to handwave away LLMs as being mere “stochastic parrots,” but at the same time we should be pragmatic and keep in mind the limitations of this technology. LLMs are not the best option for all problems, and traditional ML techniques are still important skills to have.
Without an architectural upgrade and some new insight into intelligence, the abilities of GPT will eventually hit their upper bound. I suspect we’re likely still a while away from OpenAI running into architectural limits and that GPT-5 will be every bit as impressive as OpenAI’s previous generation models.
Until we unravel the mystery of human intelligence, however, the GPT models will only ever be tools for us to use.