Software reliability happens in depth
A major difference that delineates software from other engineering disciplines is the fragility of the systems we work on. Forgetting a single rivet on a building doesn’t result in catastrophic failure, because the tolerances of standard construction materials are extreme. There’s room to make a few mistakes during construction before things become truly unsafe.
This couldn’t be further from the truth in software, where system behaviors are far more binary. Unlike the single missing rivet, a null pointer dereference in a backend system can absolutely be the root cause of a catastrophic software failure. Also unlike the rivet, the null pointer dereference either exists or it doesn’t—whereas in the physical world, faults tend to be present on a spectrum. It’s possible, for instance, that the rivet was partially installed as opposed to being missed entirely.
This fragility isn’t even a purely technical problem. The end users of software are also vulnerable to . Expedia saw a US$12m revenue increase overnight after removing a single input field from their payment form, because customers thought that the “company” input was asking for the name of their bank. An architect choosing to install a door in a strange location would never have this kind of outsized impact on the value of the final home. But in software, this degree of variability is something we need to contend with every day.
Structural engineers benefit from the natural tolerances afforded to them by the materials they work with. Us software engineers don’t get that same courtesy from the materials we work with, so it’s on us to make our own fortunes. Reliable software systems don’t happen by accident—they are the result of deliberate and thoughtful design decisions throughout the entire stack. Great software engineers are acutely aware of this and build systems with this reality front of mind.
In this post we’ll dig in to how we can write a function for looking up users from a database in a way that is safe and reliable by default, and consider a few different “levels” of reliability it could be designed for.
Example: Fetching users from a database
Problem context
I recently added product catalog webhooks to Rye, and under the hood there is a brand new webhook subscriptions system which allows users of the Rye API to control which webhooks they receive. Whenever our system writes updated product data to our database, we queue up a task which is responsible for firing a webhook to every developer who has subscribed to that product’s data.
Rye is a universal internet commerce API which lets developers sell products from a variety of different marketplaces, but the main ones we support are Shopify and Amazon. Shopify products are a simple case for this new system as Shopify product data is the same for each developer using Rye’s API, but Amazon products are a little different. Fields on our AmazonProduct type are personalized with data from the developer’s Rye account, which means that we need to have both the “base” product data and a developer’s account data in order to produce a final webhook payload.
With that context out of the way, we’ll be looking at a fireAmazonProductWebhooks function which is responsible for taking in the base webhook payload and a list of developer user IDs that should receive the final webhook. We’ll consider a few different implementations, with different levels of reliability.
Level 0: The naive approach
A quick and dirty implementation might look like this:
async function fireAmazonProductWebhooks(
data: BaseAmazonProductWebhookData,
developerIds: string[],
) {
const developers = await getUsers(developerIds);
for (const developer of developers) {
const event = formatAmazonWebhook(data, developer);
await fireWebhook(event);
}
}This code is functional, but not particularly robust. We should expect this implementation of fireAmazonProductWebhooks to give us problems as we scale up.
The problem is that it’s entirely possible for there to be a lot of developers subscribed to a particular product, which means the developerIds list can be large. We’ve written this code so it works with the entire list in one go, which means we’re vulnerable to two pretty bad failure modes:
- Our database could get overwhelmed by the query. As more developers subscribe to a particular product, the time and resources it takes for
getUsersto run will increase linearly. Past a certain level of scale we can expect our database to start running into problems—especially given that we could possibly be trying to send out lots of different products’ webhooks at the same time. Database failure is the worst case scenario for us, as the database going offline is visible to anything else trying to use it. - Our application server could run out of memory. If a user record weighs in at a few KB and we’re working with a couple million user IDs, we’re going to end up consuming many gigabytes of memory. Most web applications run in containers with far fewer memory requests than that. This isn’t as bad as the first failure mode as it’s isolated to a specific app replica, but it will still cause some service disruption.
We can obviously do a lot better here. The smallest and easiest improvement we can make is to chunk developerIds into small batches of work, and operating on those batches one at a time. This spreads out the load on our database and caps the memory used by our application.
Level 1: Chunk the work
A simple implementation of chunking using lodash looks like this:
async function fireAmazonProductWebhooks(
data: BaseAmazonProductWebhookData,
developerIds: string[],
) {
for (const developerIdsChunk of _.chunk(developerIds, 100)) {
const developers = await getUsers(developerIdsChunk);
for (const developer of developers) {
const event = formatAmazonWebhook(data, developer);
await fireWebhook(event);
}
}
}Chunk size selection is a bit of an art form. If you go too high here you lose a lot of the benefit from chunking in the first place, and if you go too low then the overheads of chunking (e.g. extra network requests) start to become relatively more expensive. A chunk size of 100 usually represents a good trade-off in my experience, but it will depend on the specifics of your workload.
With only two lines added to the body of our function—one of which is just a closing brace—we have completely solved both of the problems presented in the “level 0” implementation. At this point a lot of engineers might be satisfied and open up a pull request, but I think there’s still a long way to go before this code is production-ready.
There’s no issue with the code snippet per se, but there is a big problem with the getUsers function. While we’ve managed to limit the load caused by a large developerIds list in this particular part of the codebase, we haven’t rolled out a systematic fix. It’s entirely possible—and, in fact, only a matter of time—before another less diligent engineer on our team comes along and blows up production by passing a giant list of IDs to getUsers.
Wouldn’t it be great if we could solve this problem a single time, rather than forcing every single call site of getUsers to independently solve the chunking problem?
Level 2: Apply some systems thinking
It turns out that we can make a small improvement here by pushing the chunking logic down one level, so that getUsers is responsible for ensuring its own safety. We might also like to rename the function to better indicate its new behavior:
async function getUsersPaged(userIds: string[]) {
const pages: Array<User[]> = [];
for (const chunkIds of _.chunk(userIds, 100)) {
const users = await db.getUsersByIds(chunkIds);
pages.push(users);
}
return pages;
}
async function fireAmazonProductWebhooks(
data: BaseAmazonProductWebhookData,
developerIds: string[],
) {
const developerPages = await getUsersPaged(developerIds);
for (const developers of developerPages) {
for (const developer of developers) {
const event = formatAmazonWebhook(data, developer);
await fireWebhook(event);
}
}
}This is starting to look pretty decent! It’s now completely impossible for someone to explode our database by trying to look up a million users in one go—at least with this particular function—because we’ve systematized the fix. Solving this problem at the source acts as a forcing function on our entire codebase; we are now guaranteed a baseline level of reliability in all places where we look up user records.
Individual team members no longer need to re-solve this problem throughout the codebase, and our team members no longer need to hold this concern in their head when writing code.
In brief: we’ve reduced the skill floor of our codebase by introducing good defaults, and if you do this all over your codebase you will realize some serious compounding benefits for your engineering team’s velocity.
I like to think of getUsersPaged as “library code.” This is code that is intended to be re-used throughout your system as a fundamental building block for “application code.” Library code should be written defensively to ensure that its callers behave responsibly. This lets you keep your application code—where all the tricky business logic is—simple, making it easier to onboard new engineers and evolve in response to changing requirements.
Unfortunately, in our quest for a seamless developer experience we’ve also managed to introduce a regression. Our new getUsersPaged function makes it impossible to overload the database, but because we are eagerly buffering every single page into a big list-of-lists we are once again vulnerable to running out of memory.
Level 3: Be more idiomatic
But this too is solvable, by reworking getUsersPaged into an AsyncIterator:
async function* getUsersPaged(userIds: string[]) {
for (const chunkIds of _.chunk(userIds, 100)) {
const users = await db.getUsersByIds(chunkIds);
yield users;
}
}
function fireAmazonProductWebhooks(
data: BaseAmazonProductWebhookData,
developerIds: string[],
) {
for await (const developers of getUsersPaged(developerIds)) {
for (const developer of developers) {
const event = formatAmazonWebhook(data, developer);
await fireWebhook(event);
}
}
}Perfect. We are back to only ever holding a single page of users at a time, which means we have solved the out-of-memory issue while retaining database safety. It’s also worth noting that this final implementation is about as terse as our original bad implementation was—by leaning in to the features of our language and writing idiomatic code, we can usually end up with something that is both elegant and robust.
It’s now almost impossible to use getUsersPaged incorrectly.
Another thing worth calling attention to is that this final version of getUsersPaged is yielding entire pages of users rather than individual records. You might be tempted to surround the yield statement in a for loop to change this, but I say you should resist that temptation. Think about how and where this getUsersPaged function is being used: you are almost always going to want to work with each batch anyway, so it makes sense to lean in to that and design the API with that in mind.
The value of doing it this way becomes extremely obvious when you start chaining additional database or service calls. Let’s work through an example right now: imagine each user is associated with a “team” object, and that we also need to personalize each webhook setting according to the team’s settings.
Here’s how that looks when getUsersPaged yields each batch, rather than individual records:
async function fireAmazonProductWebhooks(
data: BaseAmazonProductWebhookData,
developerIds: string[],
) {
for await (const developers of getUsersPaged(developerIds)) {
const teamIds = developers.map((it) => it.teamId);
for await (const teamSettings of getTeamSettingsPaged(teamIds)) {
// do stuff with developers + teamSettings
}
}
}I’m assuming here that getTeamSettingsPaged is also doing chunking under the hood, and that the default chunk size for both functions is identical. That’s a pretty easy assumption to hold true, given that both of these functions are entirely under our own control and we’ve applied systems thinking across our data layer.
We are in business here. We’ve written extremely efficient application code with very minimal effort. A getUsersPaged implementation that yielded individual user records to the call site would mean we need to re-batch all the data inside fireAmazonProductWebhooks prior to running getTeamSettingsPaged. The end result would not be nearly so elegant, and there’s a very real risk that one of our fellow engineers will forget to implement the re-batching logic and instead end up sending N getTeamSettings queries to our database.
The Swiss cheese model
I like to think about this leveled approach to reliability in terms of the “Swiss cheese model” that’s popular in cybersecurity circles. In cybersecurity there is no silver bullet security measure that defends against all possible attacks; every measure will have a weakness somewhere that a would-be attacker can exploit.
So the thought experiment is that each security measure is like a slice of Swiss cheese, where the holes in the slice of cheese are like the holes in a security measure. As each slice of cheese has holes in different positions, it is possible to layer slices of cheese together so that the holes in one slice are compensated for by another.
Layer up enough slices, and eventually you reach a point where an attacker can no longer get through the stack of cheese.
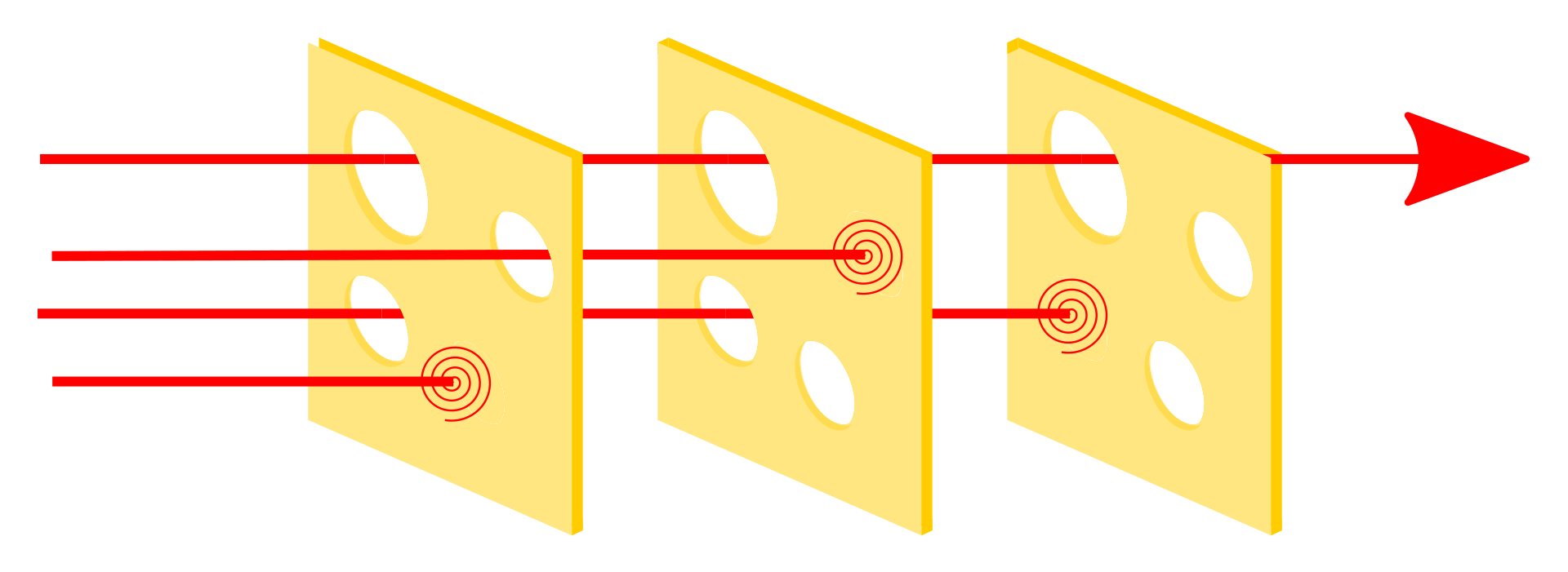
The metaphor works well when thinking about security, but it’s also pretty relevant when thinking about software reliability. Each level of getUsersPaged is kind of like adding another slice of cheese to our software that helps safeguard us against failure, and it turns out that there are a lot of places where we can source slices of cheese from beyond just our codebase.
Consider the full stack
We’ve dived deep into how we can structure client-side code to improve resilience, but the title of this article talks about resilience “in depth” for a reason. The reality is that even without putting much care or consideration into our getUsers function, a well-designed system should never fail because of a poorly implemented client.
In the real world there are many layers in the stack which would all need to fail simultaneously for getUsers to take our system offline. Here are some other levers—noting that this list is, of course, incomplete—we have at our disposal to stay up, even under adverse circumstances:
- Tech stack. Rye uses Firestore as our database for user data, which means the
infilter used bygetUsersis naturally limited to a batch size of 30. NoSQL databases such as Firestore or DynamoDB typically offer you stronger performance guarantees than something like PostgreSQL because they have less expressive query languages. This is a good thing for scalability, and it generally forces you to think through your access patterns upfront. - Database tuning. Say you aren’t using Firestore or Dynamo, and have instead opted for PostgreSQL or similar. You now have a lot more rope to hang yourself with, but you also gain access to additional knobs you can tune for your use case.
statement_timeout—among other options—can be used to set an upper bound on statement execution time, and you’re generally pretty safe setting this to something ~10 seconds. Many other databases have similar options; in MongoDB, for instance, it’s calledmaxTimeMS. - Server endpoint timeouts. Node.js servers typically have their timeout set to the
httpmodule’s default value of 120s, which is pretty long. Reducing this value almost always makes sense; most public-facing API gateway products—Amazon API Gateway included—are limited to timeouts shorter than this anyway. - Timeout propagation. In cases where you’re using microservices and making inter-service calls, you’ll need to handle timeouts correctly across process boundaries. The simplest strategy here is to attach a custom
X-Deadlineheader at the edge of your API and then propagate that header whenever you make an inter-service request. Individual services are then responsible for reading theX-Deadlinevalue and terminating themself if or when the deadline is passed. - Input validation. I’ve written previously about how I prefer using
varcharas a string type overtextbecause it forces you to bound string values in your application. The same concept actually applies to any input your application receives, and in this case ifgetUserswere calling out to another service we could add validation inside that service which ensures the number of IDs passed to it is below some threshold. A request containing 100,000 user IDs is likely excessive, and can be immediately discarded by the service. Note that when determining a limit here it’s better to be overly cautious as increasing the upper bound is a backwards-compatible change while decreasing the upper bound will break clients that are written to depend on that higher limit. - Backpressure. In cases where you have chunked work correctly but are running into throughput issues, backpressure can help avoid failures. Backpressure works by rejectng incoming requests when the service recognizes that it can‘t keep up with its workload. gRPC stands out as an RPC framework due to its native support for backpressure, which makes things easy here.
- Rate limits. Engineering teams are generally good at enforcing rate limits on external consumers, and generally very bad at enforcing rate limits on their internal inter-service communication.
Can’t I just scale horizontally?
In some cases, sure. But scaling out your infrastructure isn’t a silver bullet solution, and it’s not a substitute for getting the fundamentals right. Architecture astronautics is a dangerous profession, and trying to out-architect badly written code is kind of like trying to out-exercise a bad diet.
Imagine you have an SNS topic connected to an SQS queue, with a Lambda function set up to trigger off messages in that queue. This is a great architecture that will score you some points on the AWS Well-Architected framework, but it’s possible for this setup to fail spectacularly given the right preconditions.
If the queue in this thought experiment gets particularly busy and you haven’t configured concurrency control then the fanout of that serverless function can easily end up overwhelming the services it depends on. Concurrency control might bail you out here but if you didn’t get any of the other fundamentals correct then it’s likely you forgot this setting, too.
Even with concurrency control, it’s still possible to overload your other services. If the Lambda starts failing and your retry policy is particularly aggressive then you can end up in just as bad a position even when you are only trying to process a few SQS messages.
Rate limits—and other reliability primitives like database tuning—let you get ahead of this problem before it materializes as a real business concern. And while designing complex architectures is something you do on a case-by-case basis, setting rate limits or configuring a SQL query timeout is something you do exactly once and go on to benefit from forever. The cost-benefit and simplicity tradeoffs are so heavily tilted away from fancy architectural choices here—you are always better off focusing on the fundamentals before you start considering ways of adding more cloud into the mix.
Conclusion
We work in a unique engineering discipline where things are simultaneously fragile and completely under our control. We might not have the same inherent tolerances afforded to us as a structural engineer, but we have other tools at our disposal which we can use to compensate. It’s a lot easier to reproduce and test a software failure than a structural failure, for one thing. That software exists in a complete sandbox is pretty powerful, and gives us a uniquely fast feedback loop for identifying and fixing reliability issues. It’s important to make the most of that loop; testing and load planning aren’t particularly sexy activities and can feel “slow,” but the time spent on these activities pale in comparison to how things are in other industries.
We also have some flexibility here in choosing what level of reliability is appropriate for our business context. A full-blown level 3 solution may not be what you reach for when proving out an MVP, while it might be the bare minimum required in a healthtech context.
I also think it’s important to have some perspective on software engineering more broadly: failures are a natural and expected outcome from sufficiently complicated software systems, and—at least for now—it doesn’t seem possible for us to comprehensively solve all reliability issues. Code is too brittle and the failure modes too obscure for us to anticipate all possible faults ahead of time. The best we can do is apply fundamentals and systems thinking the best we can to make our code as safe by default as possible.
Consider automated deployment pipelines for a moment. Would we have needed to come up with a mechanism for automatically and immediately delivering fixes to software systems if software systems were always completely reliable? My take is that a lot of the investment in CI/CD systems over the years has been driven by an understanding that software systems are innately fragile, and the only way of getting a 90% reliable software system up to 100% reliability is by progressively testing and improving the system in a production environment.