Using Terraform plan to write your IaC
Using infrastructure-as-code solutions such as Terraform is a great way to keep your cloud environments consistent and auditable, but it can be difficult to get started. Clicking around a cloud provider's console to set up infrastructure is a lot easier than writing text in a .tf file, and most tutorials aimed at beginners aren't written with Terraform in mind.
How can you write infrastucture-as-code if you're not quite sure what you're doing?
How does Terraform work?
With Terraform, you write code in .tf files to represent your infrastructure instead of setting it up by hand using your cloud provider's management console. Terraform files have quite straightforward syntax that's easy to read:
resource "aws_sqs_queue" "main" {
name = "my-queue"
}The previous code block creates a queue on AWS called my-queue. The queue can be referenced elsewhere in the file by using its path, which is aws_sqs_queue.main in this case.
Terraform code declaratively describes what you want your cloud infrastructure to look like, and the tool is then responsible for figuring out how to transition your cloud infrastructure from whatever state it's currently in to the desired state expressed by your code.
To see what actions Terraform will take to achieve your desired state, you can run terraform plan. To actually execute those actions, you can run terraform apply.
Once you've ran terraform apply for the first time, a "state file" will appear in your working directory. The state file stores information on all of the infrastructure created by Terraform–if you run the previous code block and look at the state file, you'll see the queue.
The state file is the thing that makes Terraform feel like magic. The state file can be used in two ways:
- Terraform can read the state file, and then look up the resources inside your cloud account. If the resources in the cloud differ from what's in the state file, it means they have drifted from your configuration and will need updating by Terraform.
- Otherwise, Terraform can compare the contents of the state file against the code you've written. If there's any difference there, it means you've modified your infrastructure-as-code since the last time you ran
terraform applyand so Terraform will need to make updates to your cloud account.
Understanding how the state file works is an important part of working with Terraform, as there are a lot of real-world situations where working directly with the state file is necessary. For this guide, we only really need to understand drift detection.
Using Terraform plan to write IaC
The trick here is that because Terraform can detect drift, it's possible for you to set up your infrastructure in the management console and then use terraform plan to figure out retroactively what your code should look like.
You can start by applying the first block of Terraform we looked at to create the my-queue queue. After it's finished applying, you can go into the AWS console and change a property on the queue via the UI–for instance, you could change the "visibility timeout" from 30 seconds (the default) to 1 minute. If you run terraform plan after doing that, you'll get the following output:
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
~ update in-place
Terraform will perform the following actions:
# aws_sqs_queue.main will be updated in-place
~ resource "aws_sqs_queue" "main" {
id = "https://sqs.us-east-2.amazonaws.com/878931269970/my-queue"
name = "my-queue"
tags = {}
~ visibility_timeout_seconds = 60 -> 30
# (11 unchanged attributes hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.Remember that at this point, our Terraform configuration and our actual cloud resources aren't in sync with each other. Our Terraform configuration is set up to create a queue with all of the default settings, whereas our real queue has a custom visibility timeout.
When terraform plan gets run, Terraform detects the drift in the real infrastructure and attempts to fix the drift. In general, if we run terraform plan at this point and see any changes in the plan output it means that theTerraform code is incomplete and needs to be modified to match what's set up in the cloud.
When you follow this strategy for writing infrastructure-as-code, the necessary changes are usually very easy to identify. In this case Terraform wants to change the visibility_timeout_seconds attribute of the queue from 60 down to 30, so all that's needed to be done is to add a visibility_timeout_seconds attribute to the queue resource with a value of 60, like so:
resource "aws_sqs_queue" "main" {
name = "my-queue"
visibility_timeout_seconds = 60
}Rerunning terraform plan reveals that the code is correct and matches the changes made in the console:
No changes. Your infrastructure matches the configuration.So long as you know how to create an empty resource in Terraform, you can usually use this trick to configure the resource inside the console and then figure out the code you need with terraform plan. If you're not entirely sure how to create an empty resource, then all you need to do is look at the AWS provider's documentation for the resource you're interested in, and fill out any required arguments. Here are the docs for aws_sqs_queue, for instance, and in the case of this particular resource there are no required arguments at all! A completely empty queue like below will work just fine:
resource "aws_sqs_queue" "foo" {}This doesn't work for all attributes!
While the technique using terraform plan will work most of the time, there are some attributes in the AWS provider which don't seem to get picked up on by drift detection. In the case of an SQS queue, one such attribute is the redrive_policy. If you go into the console and add a redrive policy to your queue, then Terraform will report no changes when you plan the infrastructure.
This is pretty frustrating, but there is a workaround involving use of terraform state. Terraform is actually capable of recognizing the redrive_policy has changed and will update the state file to reflect changes made in the console, but the AWS provider simply doesn't correct drift on attributes like redrive_policy.
The alternate workflow is to first run terraform refresh. If you look at the output of terraform plan you'll see that the first thing Terraform does is refresh the state of all the resources its managing before going on to plan how to marry your real infrastructure to your desired infrastructure, and terraform refresh is a command you can run that only performs the first part of that workflow.
Then, you can run terraform state show ${address}. The address of a resource in Terraform is a dotted path consisting of the resource's type and logical name. In the case of our queue, its address is aws_sqs_queue.main, so we would run terraform state show aws_sqs_queue.main. The output from that command looks like this:
# aws_sqs_queue.main:
resource "aws_sqs_queue" "main" {
arn = "arn:aws:sqs:us-east-2:878931269970:my-queue"
content_based_deduplication = false
delay_seconds = 0
fifo_queue = false
id = "https://sqs.us-east-2.amazonaws.com/878931269970/my-queue"
kms_data_key_reuse_period_seconds = 300
max_message_size = 262144
message_retention_seconds = 345600
name = "my-queue"
receive_wait_time_seconds = 0
redrive_policy = jsonencode(
{
deadLetterTargetArn = "arn:aws:sqs:us-east-2:878931269970:my-queue-deadletter"
maxReceiveCount = 10
}
)
sqs_managed_sse_enabled = true
tags = {}
tags_all = {}
url = "https://sqs.us-east-2.amazonaws.com/878931269970/my-queue"
visibility_timeout_seconds = 60
}Here we can see the entire queue object as it's stored in state, and we can see that redrive_policy has changed. The downside of going through state like this is that you don't get the nice diffing behavior of terraform plan--it's on you to scan through the definition of the object and see what has changed, which is why I like starting off with showing the terraform plan workflow.
If you're just experimenting, then there's a way to make this workflow a little nicer. Turn the directory with your Terraform code into a Git repository, and then commit your state file right before executing terraform refresh. Now if you run a Git diff on the state file you'll see exactly what changed. You can't really do this on production systems, though, because in those cases a. you should be storing your state file in an S3 bucket or similar and b. you really don't want to risk pushing your state file to source control, because it's completely unencrypted and contains secrets.
Caveats
There's no such thing as a free lunch in software engineering, and this strategy is no exception. Here are a couple of things you'll want to keep in mind.
Be careful of implicit resources
The one limitation to this strategy is that it only works well when you have all of the necessary resources initialized within your Terraform file. So long as they're in code, your terraform plan run will pick up any drift and report them.
If you miss a resource, then Terraform can't perform drift detection. Usually this is pretty easy to avoid by only using the console to modify resources, and relying on Terraform whenever you need to create new ones. In some cases, however, your cloud provider might wind up creating resources automatically when you configure infrastructure.
A good example of this happening is with Cognito user pools. If you go through the setup process for a user pool and enable email delivery with SES or text message delivery with SNS, the console will automatically create a role for your user pool which grants it permission to use those other AWS services.
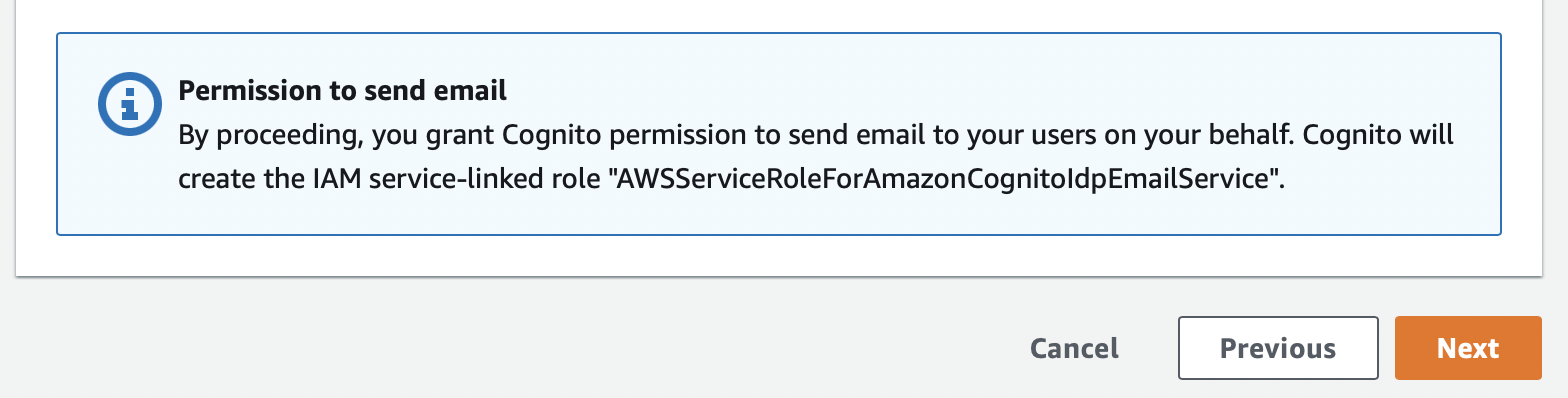
On AWS this is easy to spot–the console will always show a notice somewhere in the UI telling you when resources will be created automatically. So long as you keep an eye out for these notices, you shouldn't miss anything.
Be mindful of naming restrictions
One of the big advantages of using Terraform to manage your infrastructure is that you can write the code once, and then apply it to multiple different cloud accounts. Doing this gives you separate staging and production environments with no additional effort.
Be mindful, however, that resources like AWS S3 buckets must have a globally unique name. If you hardcode your buckets name with a static string, then applying your infrastructure to multiple different environments will fail. It's a good practice to namespace your resources to make sure you won't run into a conflict.
variable "ENVIRONMENT" {
type = string
}
resource "aws_s3_bucket" "main" {
bucket = "my-${var.ENVIRONMENT}-bucket"
}Here the name of the environment gets included in the name of the bucket. This way, the staging bucket will be named my-staging-bucket and the production bucket will be named my-production-bucket. These names are different, which means you won't run into issues applying the infrastructure to multiple environments.
IaC doesn't have to be difficult
There's a lot of complexity in our industry, and it can be tempting to reach for ClickOps to save on having to learn yet another tool. IaC is a massive productivity win, however, and I would urge you to manage all cloud infrastructure using a tool like Terraform or CloudFormation.
In the case of Terraform, it's actually really easy to write IaC--and it's even possible to eschew learning how to do it altogether. If you provision shell resources with Terraform and then customize them using the AWS Console, you can use terraform plan and the state file to instantly figure out what your Terraform code should look like for your desired configuration.
In exchange for a few minutes of time tinkering with the Terraform CLI, you gain the ability to immediately spin up identical-looking environments (e.g. staging or QA), are able to source control your infrastructure, and are able to completely tear down and recreate your infrastructure in the event of a disaster.