Alternative NZOI training site: Progress update
A few weeks ago I had the privilege of teaching C++ to a group of bright high school students during NZOI's annual training camp. In my retrospective article about that experience, I mentioned wanting to build out some better tech for NZOI so as to better enable students to train and collaborate together on problems hosted on NZOI's training website. While I haven't made quite as much progress as I would have liked to by now (I'm a busy person—and always looking for more work), I'm reasonably happy with where things are at and would like to share some of what I've done with you today.
The first step of any new project is to perform user research and gather requirements. During the time I taught C++, I had asked the girls for their perspective on anything they found "annoying" about the NZOI website--big or small. This gave me a small list of things to work from, and then I observed how the rest of NZOI's students operated in order to pad out that list. Finally, I added some of my own requirements--because ultimately I want this system to be useful for myself if nobody else ends up using it.
Here are some of the things I gathered:
- Discord is a very popular medium of communication for NZOI students, but the integration between the training site and Discord leaves something to be desired. As an example, linking to problems doesn't give you nice previews.
- The training site does not work well on mobile phones.
- When solving a problem on the training site, you can either upload a code file or write code directly on the website. The code editor is just a plain text field with no syntax highlighting.
- There's no search feature on the training site, so you need to hunt around the groups you're in to find a particular problem.
- The typography on the training site is small and hard to read depending on your eyesight and monitor.
- After submitting a solution to a problem, you need to manually refresh the page in order to get your results.
- There's no dark mode interface, which makes using the training site at night uncomfortable.
I'm specifically focusing here on end-user concerns; there are similar things I've recorded about the administrative interface of the training website which I may or may not eventually get around to dealing with--but my principal concern is improving the UX for students.
Discord
I figured Discord was a good task to tackle first, as I assumed it would be easy to build a bot that presented nice previews of problems. I'd never built a Discord bot before, but in my opinion the mark of a good software engineer is their ability to quickly learn to use new technologies. After a few hours, I had a bot which could generate previews like the following:
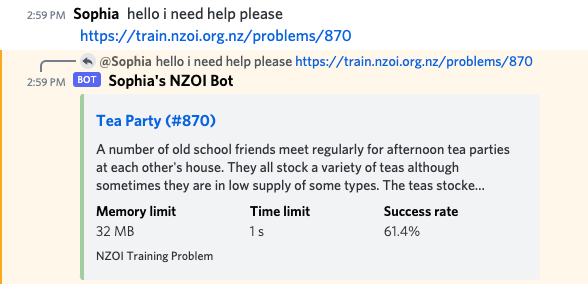
The main reason this feature took as long as it did was because I needed to reverse engineer the authentication flow for the existing training site. As I'll explain later, there is a nascent API available but authentication is not exposed which means you need to programmatically submit their online login form and retrieve the session ID you get assigned in order to make subsequent requests against (potentially) privileged resources. As it turns out, axios by default will follow HTTP redirects but won't keep track of cookies. This behavior is surprising, because I would expect an HTTP client to either do both of those tasks (as in Python's requests library) or neither (like the standard Javascript fetch function). The issue is that signing in to train results in an HTTP 302 redirect to the home page, and if you follow that redirect then you lose the Set-Cookie header sent back from the endpoint which handles your login request--making it impossible to retrieve the authenticated session ID.
After figuring out the cause of that issue, the rest was pretty straightforward. My original claim to fame is in scraping legacy systems for data analytics, so parsing the HTML of a problem page was quite easy. I generally like axios--its API is a lot more ergonomic than fetch, and it's popular amongst Javascript developers which makes onboarding new employees easy, but some of the default options are a bit unintuitive and the batteries-included nature of the library means that sometimes it does too much for you. In future I'm going to default to a simpler HTTP library as I've had a number of these kind of issues with axios over the years, and I don't expect the situation to get any better soon as breaking API changes are not too uncommon.
The next three features I wanted for the Discord bot were:
- A way to link Discord accounts to NZOI training accounts, so that I can quickly click on a Discord user and get sent to their profile page. Very useful for when someone has a question about one of their code submissions!
- A hints system. The "unofficial" NZOI Discord has a lot of problems caused by people accidentally spoiling problems when trying to help another person out, because it's easy to forget to wrap your message in spoiler tags.
- A wiki-style system which turns Markdown files into Discord channels, in order to better organize resources, tutorials, and notes.
The first and second features are pretty easy--a bit of SQL keeps track of account associations, and hint-problem associations--but the third feature is still a work in progress. Below is a screenshot of what these "guide channels" look like:
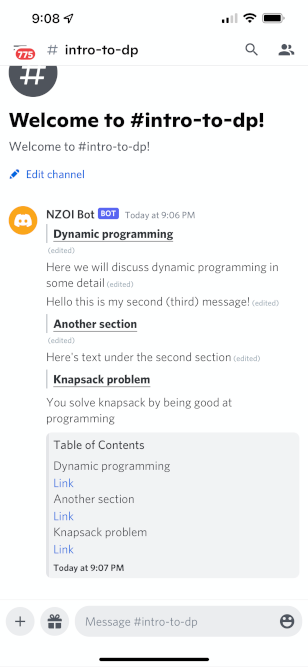
Top-level headings are extracted from the Markdown files and transformed into a table of contents at the bottom of the channel. Clicking an entry of course scrolls you to the message which contains the header. One complexity here which isn't totally obvious is that Discord has a 2,000 character limit per message which can be hit surprisingly easily--I've added some custom syntax to the Markdown files which allow authors to explicitly indicate where they would like messages to finish. Another area where this is useful is for inline images: images attached to text messages (in my opinion) look very unappealing compared to images posted all on their own.
Unfortunately, this feature isn't quite ready because updating the guide after deploying it for the first time is quite buggy--especially when second level headings are involved. When I get the time I'm going to patch up this feature so that it's a bit more resilient, and then release it to my server of PC4G girls for feedback. I'll likely open source the Markdown converter as I can imagine it being useful in a variety of different contexts, and not just for NZOI. So far, feedback on my Discord bot has been very positive despite it being incomplete which I'm pleased about.
NZOI API Client
Next on the agenda was building a library for interfacing with NZOI's API. I'm very happy with how this project has turned out, and you can access the code on Github or install it by running yarn install nzoi-api. Currently there's very little documentation available as I haven't had time to sit down and write things out, but if you've ever used the Stripe client for Node.js you'll likely feel at home as I've modelled my API client off that one. Stripe does a really good job of designing fantastic developer experiences, and as the saying goes: great artists steal.
NZOI's API is incomplete and doesn't have some functionality which I would greatly benefit from. Here are two examples:
- There's no endpoint for fetching a problem; which is why I parse the HTML instead.
- When fetching objects like problem sets, the associations that object has isn't returned. To make this a bit more concrete, fetching a problem set does not retrieve the list of problem IDs associated with the problem set!
I did a bunch of poking around the training site's code, wrote up a proposal for new endpoints for the existing developers, and once I received their approval I wired up the new endpoints and created a pull request. That PR is currently awaiting review, and I'm optimistic that it will be merged in soon-ish. Once the API gives me a bit more data, it will unblock me on completing my alternative train site.
The big difficulty here was in getting the NZOI training site up and running--and this is recognized to be an issue by the volunteer developer team. It's a very old (about a decade) Rails project, and it is very particular about its environment. There's no containerization tech in use, so getting set up means installing everything manually on an Ubuntu 16.04 virtual machine. It took me a few days to get everything sorted (and I took a shortcut--I skipped installing some dependencies such as v8, as compiling that from scratch takes a long time).
While Docker has issues (particularly when it comes to I/O on macOS) and you can sometimes find yourself in weird situations where you need to delete a container and create a new one, the experience of getting the old training site up and running has really reinforced my love for containerization--it really, really does make onboarding a whole lot easier when you can just type docker compose up into a terminal and immediately have a working development environment.
My point today is that, if we wish to count lines of code, we should not regard them as “lines produced” but as “lines spent”: the current conventional wisdom is so foolish as to book that count on the wrong side of the ledger.
It's also reinforced my conviction that it is necessary to have someone on your team working on platform concerns, because if you find yourself a few major versions behind on enough of your dependencies then you risk finding yourself in a situation where it is excruciatingly difficult to get back up to date. Lines of code are a liability, and legacy code can and will sink your software company if you aren't proactively managing it.
Alternative frontend
Finally, the fun part: actually writing the alternative training site interface. As the training site has a CORS policy which restricts other domains from fetching it, I also need a thin backend to proxy requests through to the real training site so that my frontend is able to actually retrieve data. As Azure is the cloud provider I have the least experience with (most of what I do is on either AWS or Google Cloud), I'm intending to host the backend for this project on Azure using their serverless products.
On the frontend, a lot of packages I've used in the past have had version bumps recently. Instead of trying to use a radically different piece of technology for my frontend, I'm being a bit more incremental and using this as an opportunity to get up to speed with the latest and greatest versions of popular libraries such as React Router. Version 6 of React Router is awesome--the killer feature of Angular is router-outlet, and now we have the exact same feature in React. It's a gamechanger for frontend development and makes building consistent UIs way easier.
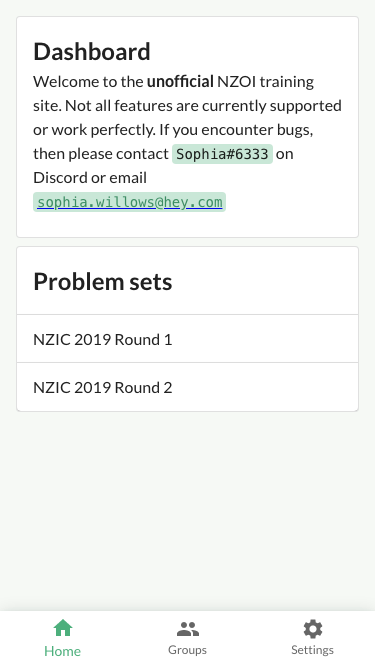
Here's where I'm at so far:
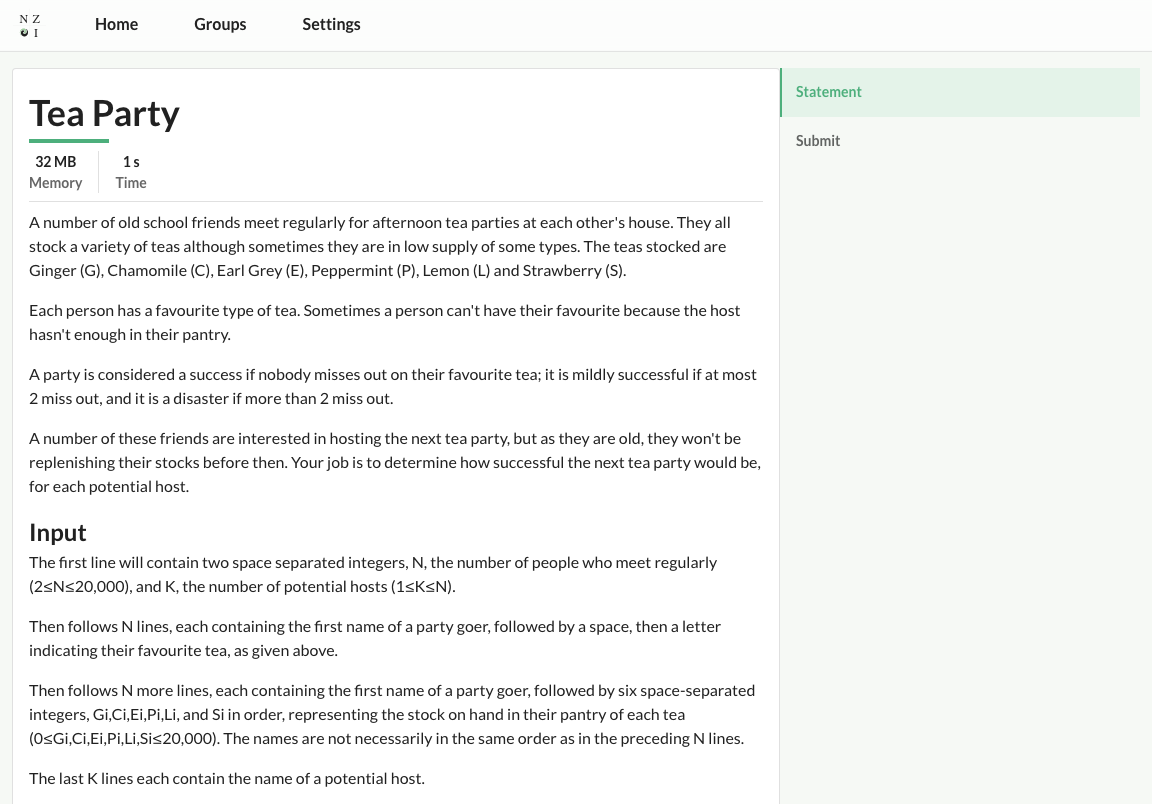
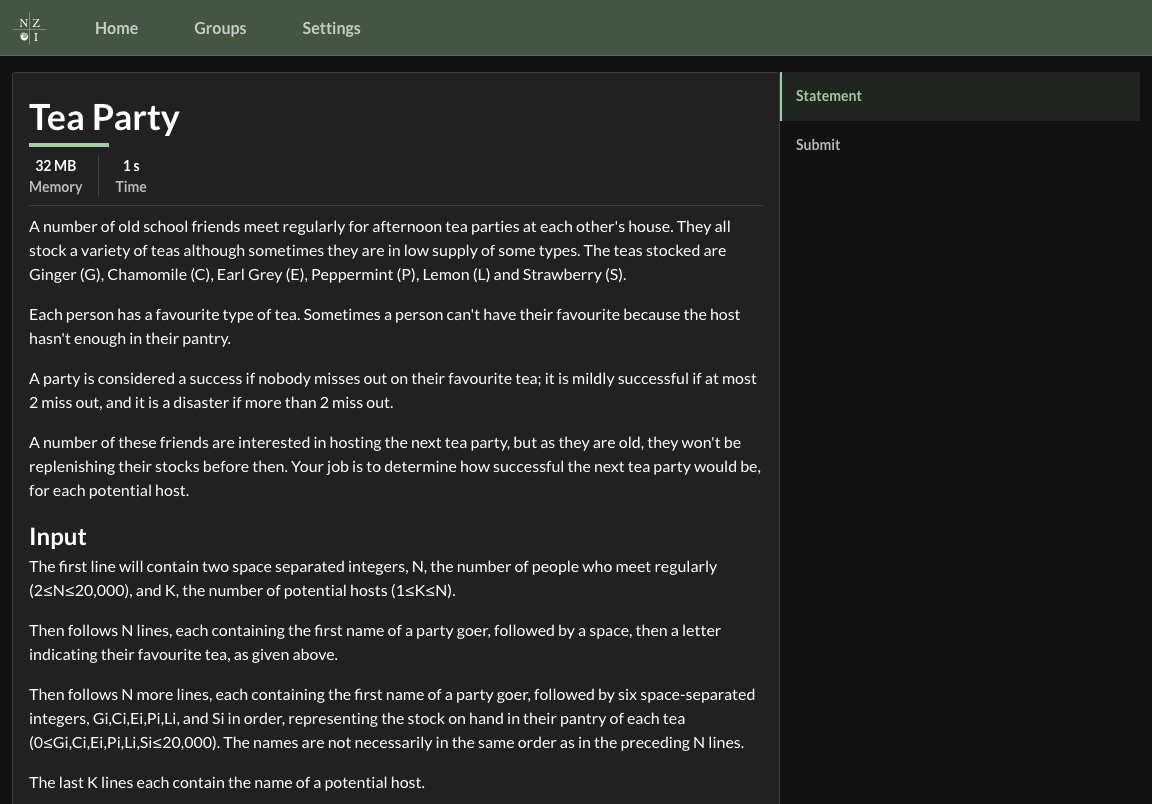
This app is not like Instagram where it's all about images and video--this is a text heavy app, and I want the text to be the most important thing on the page. Large font sizes, liberal use of whitespace, and a clean, minimalist design are what I'm going for here so that the text really pops. A splash of color to assist with emphasizing the information hierarchy (such as slight underlines beneath level one headings) also helps guide the eyes to the content of the page.
A minor point, but I had to saturate the NZOI brand color a bit more in order to get the light mode theme looking nice, as the contrast ratio between white and their pastel green is too low to stand out. Implementing a dark mode or light mode isn't a matter of simply inverting the colors of your existing design system--the human eye interprets color differently when the background color is dark, and general UI design principles such as having the "closest" UI element be the lightest still apply when designing dark modes. I think there's still a ways to go with my dark mode (truthfully I prefer light mode almost always) but for a first pass I don't think it's too bad.
One of the additions I made was to use the Monaco editor (the same text editor Visual Studio Code uses) on the submit page, which greatly improves the ergonomics of writing code directly on the site compared to writing code into a plain HTML text field. By using Monaco, users get all the niceties of a modern browser right there on the page without needing to install a text editor (remember that NZOI students come in a variety of ages and experience levels, so we can't assume they'll all have a development environment set up).
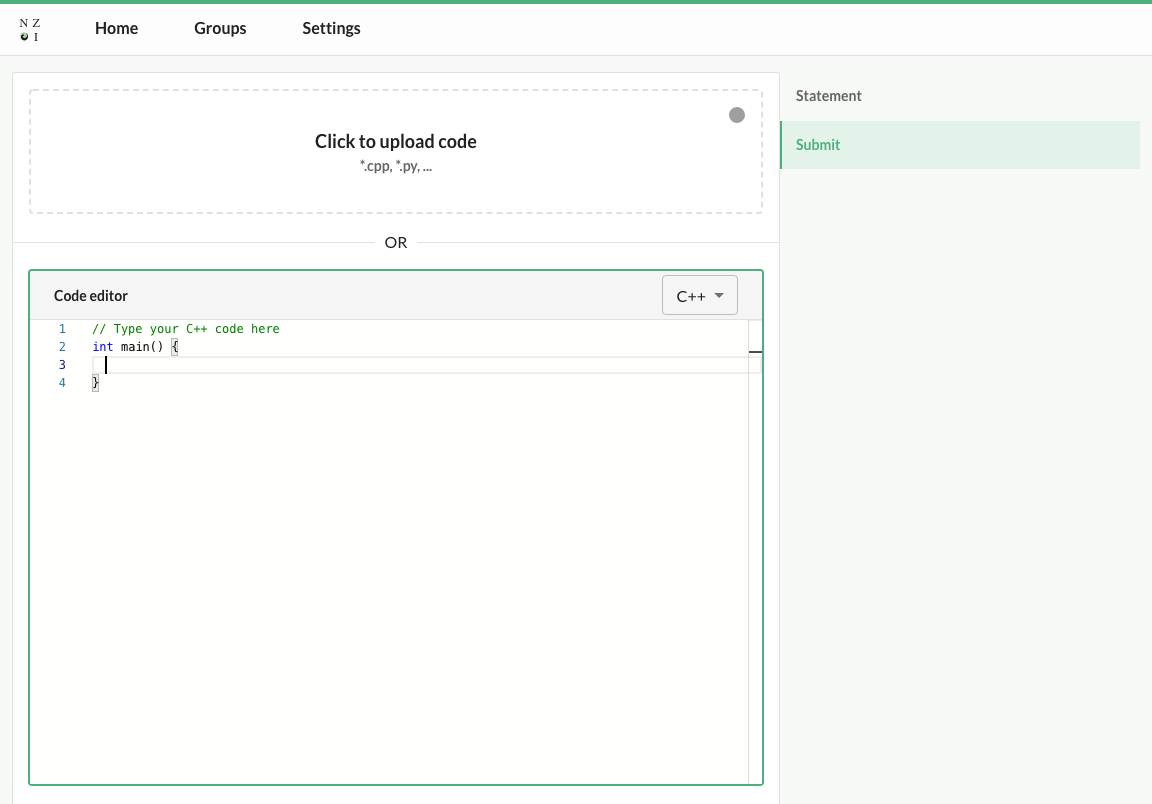
I also optimized how users upload files--on the official training site, users need to explicitly select the programming language their file is written in whereas my version infers the programming language based on the file extension which removes a potential point of user error. Small UX tweaks like that can have a big impact on the success of a product--one time Expedia managed to boost their revenue by $12m simply by removing an optional field from their checkout form.
Finally, the design is of course responsive and works well on mobile phones. This was an especially important feature for me, as often when I'm helping out students with a code issue I'm out and about on my phone and don't have a large display handy.
Next steps
I'm going to try and get my Markdown-to-Discord-channel converter bugfree so that I can start managing tutorials and resources in a more sane manner than manually editing Discord messages. It will be open sourced once it's finished in case other people also find it to be a useful tool. Aside from that feature, I'm largely done with the work on my Discord bot--Discord.js is a really nice library, and allowed me to get a lot of work done very quickly.
For the frontend, I'm waiting on my pull request to be merged (or for issues with it for me to fix to be identified) so that I can get unblocked on some key features of my unofficial training site. Most importantly, I need access to relational data through the API such as which problems belong to each problem set. Right now the home page of my training site is just using dummy data because I can't get access to the real data (unless I were to do some scraping--but what's the point when the endpoints could go live at any point?). Once I've got the basics down (viewing and submitting problems) I'll release it to my PC4G group for initial testing, iterate a bit more, and then offer it as an alternative UI to the rest of the NZOI students. If it turns out to be popular, I might end up implementing some of the admin UI as well--but we'll see how it goes.
Thanks to the team at NZOI for signing off on the additional API endpoints I needed, and I hope that the tools I'm building will prove to be valuable for the organization.