GPT-4 rate limits are brutal; use GPT-3.5 instead
Something which doesn’t seem to be getting much attention is just how punishing the rate limits are for using GPT-4 over OpenAI’s API. They’re really low, and if you’re building anything on top of GPT-4 you need to implement strategies for working around them very early on in your product’s lifecycle.
At the moment the limits for the 8K context model are 200 requests per minute, or 40,000 tokens per minute—whichever gets hit first. The 32K context model has an even lower request rate limit of 20 requests/min, but a higher token limit of 150,000 tokens/min.
Most people using GPT-4 will be using the 8K context model, because the 32K model is significantly harder to get access to. The 200 requests you get to make each minute disappear very quickly, even for small projects. It’s only 3.33 requests per second!
Things are different now!
I wrote this post back in June 2023, and the situation has changed quite a bit since then. The new GPT-4 Turbo model is quite a compelling option for production use cases, and rate limits have been bumped up significantly. If you still have rate limiting issues, I also wrote a follow up post which goes over a few strategies for working around them,
OpenAI are aware that this is restrictive, and even say this on their rate limits documentation page:
In its current state, the model is intended for experimentation and prototyping, not high volume production use cases.
It’s clear that GPT-4 has significant limitations when it comes to building products, and these limitations are unlikely to disappear any time soon.
Why are rate limits so low?
When I first applied for GPT-4 access I received it within a week, but it seems to be taking a lot longer for people to get access today. It’s easy to see why: the demand for this service is massive, and OpenAI doesn’t seem to be able to add capacity quickly enough to match the demand.
PromptLayer publish an OpenAI middleware which automatically logs your requests. You never “lose” a prompt ever again because they’re all stored in PromptLayer’s database, and they also offer some additional features such as performance monitoring and request tagging.
With this data, they’re able to publish a graph that visualizes GPT latency over time. At the time of writing, the graph looks like this:
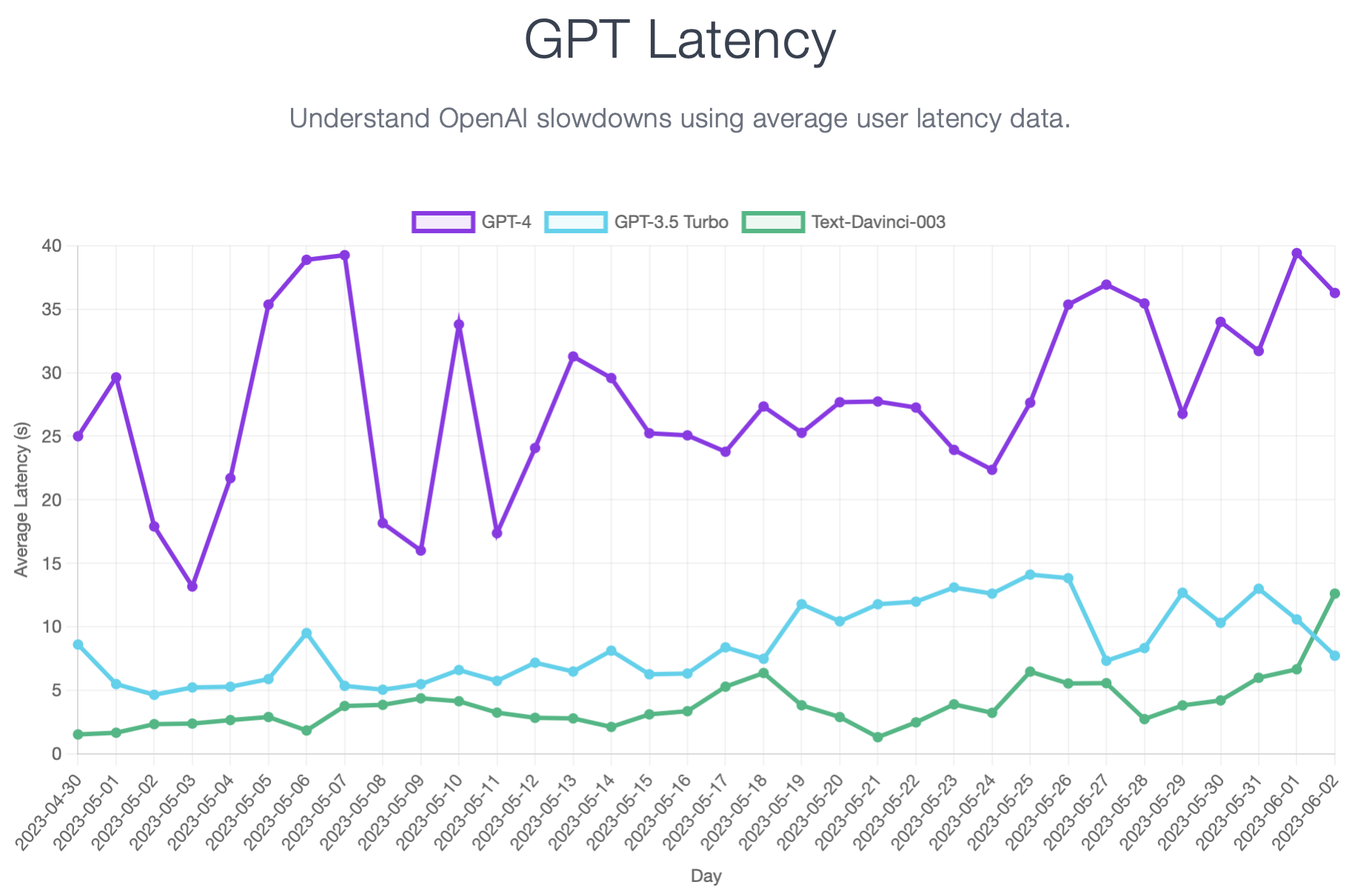
Looking at the graph, the gpt-3.5-turbo and text-davinci-003 series are fairly stable while the gpt-4 line is all over the place. Anyone who’s worked in (Dev)Ops understands that this is indicative of a service that’s struggling to meet demand. Note that the X-axis is at the scale of one entire day: latency doubling from one day to the next is not a good sign.
We’re in the middle of a gold rush where everyone’s trying to build the next big thing on top of GPT, and GPT-4 gives really good results with very little investment.
How can you work around GPT-4 rate limits?
The best and only solution is to not use GPT-4. As OpenAI publicly state, it’s best used for prototyping and experimenting. You can whip up a proof-of-concept in an afternoon using GPT-4, but you’re not going to be able to sell that proof-of-concept at any level of scale with rate limits where they are.
Instead, production workloads are stuck using GPT-3.5 for the foreseeable future. The rate limits for GPT-3.5 are significantly better, sitting at 3,500 RPM and 90,000 TPM—almost 18x higher than for GPT-4—and it’s also actually possible to get rate limit increases for GPT-3.5 when you do exceed that limit.
In my experience, there are very few things you can do with GPT-4 that are impossible to achieve with GPT-3.5. It’s just that getting those outputs is a lot harder, and requires far more creative and precise prompting. Oftentimes you’ll need to rethink your approach and decompose your prompt into several smaller prompts, each solving one aspect of the problem you’re trying to solve before later combining them back together.
Bear in mind that GPT-4 is at least 15x more expensive than GPT-3.5, which means you can prompt fifteen times for every one GPT-4 prompt and still break even on API costs. Response times are also much better for GPT-3.5 than they are for GPT-4, so it’s not uncommon to be able to waterfall 2-4 GPT-3.5 requests and still generate a response before GPT-4 can.
You simply can’t build real products that are used by more than a few thousand users on top of GPT-4. The rate limits don’t let you.