Strategies for managing GPT-4 rate limits
The upper limit for GPT-4 rate limits have significantly improved over the past few months. When I first wrote about them, they capped out at a meagre 200 requests/minute, or 40,000 tokens/minute—whichever got hit first.
Today the GPT-4 rate limits automatically scale up to 10,000 requests/minute or 300,000 tokens per minute. A day ago the caps were half of that. OpenAI have seemingly overcome their infrastructure bottleneck.
You can see this reflected in PromptLayer’s GPT latency graph. Still pretty spikey, but both the peaks and troughs are lower than they were back in May:
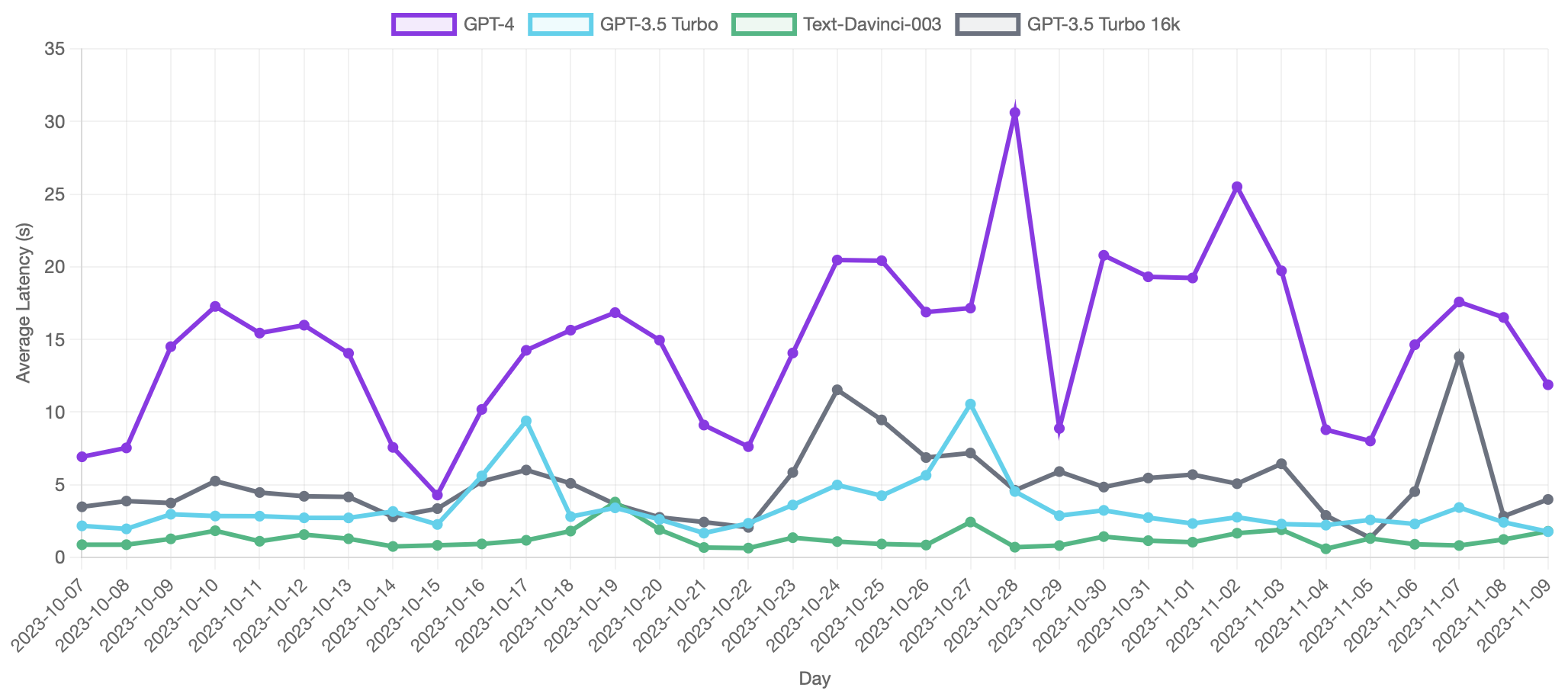
Having said all this, the rate limits are still pretty low and if your company is growing and has a heavy reliance on GPT-4 it’s only a matter of time before they start to bottleneck you. 10,000 requests per minute isn’t the problem—it’s the 300,000 tokens per minute.
It’s a simple math problem. To exhaust that requests/minute quota you’d need to average only 30 tokens per prompt, which is way lower than what your actual average will be.
Another way of thinking about this: the old rate limit was enough for about five context windows. The new rate limits are enough for 37 1/2. You can get through that pretty quickly.
The following is a list of strategies you can employ to reduce your usage of GPT-4 and stretch the rate limits further.
The gold standard here will always be to shift workloads off of GPT-4 and on to smaller, less capable models but this either requires much more prompt engineering, or in-house ML expertise to build a custom model. I’m not focusing on those heavy-handed approaches here, and instead these are strategies you can apply around the edges of your existing system.
Use the moderations endpoint
OpenAI maintain a moderations endpoint which takes in text and tries to identify whether it’s abusive or otherwise inappropriate. Unlike their other API offerings, this endpoint is completely free to use—so long as your purpose is to validate GPT inputs or outputs.
If your product is taking in arbitrary user input, then the moderations endpoint is a good first line of defence. If you find that the moderations endpoint flags an input as inappropriate, you can bail out early and avoid draining your GPT-4 rate limit.
Here’s what that looks like in TypeScript:
const moderation = await openai.moderations.create({
// Note: Like the embeddings endpoint, you can send
// an array here if you want to check multiple blocks
// of text in one request.
input: userInput,
});
if (moderation.results[0].flagged) {
// Bail out of bad user input
}
// Proceed with main pipelineNote that this specifically only handles inappropriate input as defined by OpenAI. Over at AdmitYogi Essays, for instance, we want to bail out early if a user has submitted something which doesn’t look like a real admissions essay. The moderations endpoint doesn’t help with that, so we need a purpose-built classifier for the task.
Depending on the product you’re building this may or may not have a significant impact on your GPT usage.
Users have a surprising tendency to abuse chat bot applications so if you’re building a customer support agent the moderations endpoint will be quite impactful. On the other hand, if you’re building a book recommender then it’s less likely that users are regularly typing in things that would be flagged.
“Load balance” with Azure
You can host your own private OpenAI deployment via Microsoft Azure, and the rate limits on that deployment are completely separate from those on your OpenAI account. This gives you an immediate rate limit boost that can buy time for more involved solutions.
The idea is that you use the public OpenAI API, and upon receiving a 429 status code you fall back to using your private OpenAI deployment (or vice versa).
I’m not too sure what the state of things is like now, but last time I set up GPT-4 on Azure I had to wait months to get through the waitlist. If your application is growing then it pays to get on top of this sooner rather than later.
Cache your GPT-4 responses
This one’s a pretty obvious solution, but depending on your level of expertise you might not know how to do this. Caching based on an exact string match is simple enough, but how often are users submitting exactly the same input to your system? It depends on your app, but I find that caching is only effective when you can fuzzy match over past inputs and outputs.
Vector search is the solution to this problem. “Embeddings” is a generic term in machine learning, but it is exploded in popularity recently with the advent of LLMs. Computers cannot natively process objects like words, pictures, or audio, and the solution to that problem is to convert these objects into vector format.
A vector is a 1-dimensional array of numbers, and you can think of an embedding vector as a sort of compression for semantic meaning. That is, vectors which are close together in vector space tend to mean similar things to each other.
Kawin Ethayarajh has a blog post digging into this deeper if you are interested in learning more.
Vector databases like Pinecone are optimized to perform similarity search on vectors, but depending on your scale you might not need it. The pgvector extension adds similar vector search capabilities to postgres and it performs reasonably well even on tables containing 1 million OpenAI embeddings.
The idea is that you want to create and store an embedding of your user’s input alongside your GPT result in some sort of datastore. Then when you receive subsequent inputs, you create an embedding from that input and check to see if there are any highly similar embeddings already inside your database.
If you find a match then you return the cached result and save on a GPT-4 API request.
The exact threshold you’ll use for identifying a cache hit will vary based on your use case. At Crimson we have a feature which generates ~10 extracurricular activity concepts in parallel, and we use embeddings to check that we haven’t wound up generating duplicates.
For that use case, we consider any two vectors with a cosine similarity greater or equal to 0.91 as duplicates. We then regenerate them with an altered prompt to ensure diversity.
Note that the user’s input on its own might not constitute a good global cache key. That extracurricular activity recommender, for instance, runs against a student profile and we perform a bunch of database lookups to pull in values for our prompts. The user’s input is a small piece of the puzzle, here, so we’d need to be more intelligent.
One option is to concatenate the user’s input with the values you’ve looked up from the database and compute the embedding vector of the resulting string.
Another option is to partition your cache. Most often this comes in the form of per-user caches to avoid the possibility of leaking data, but in the case of our recommender we could come up with a smart way of hashing our database values and use that as a partition key.
Lots of details to work out and tailor to your specific use case, but implementing caching correctly can hugely reduce your GPT-4 usage. Even a 20% cache hit ratio effectively increases your rate limit by 25%.
Summarize your context window
The underlying principle at play here is that as your customers go back-and-forth with your application, you’re building up a big message history. Every time you need to respond to a new message, you’re sending that big message history to GPT as prompt tokens and accruing more tokens/minute usage.
Broadly, there are two solutions:
- Cap the amount of history you send to GPT. Instead of filling the entire context window, you might only send the last 10 messages. This has the downside of making your chatbot appear more “forgetful.”
- Summarize your message history. Use a cheaper model like GPT-3.5 to reduce the token count of your message history in the first place, so that you end up feeding fewer tokens to the more expensive and rate limited model.
Option 2 is the secret sauce all good chat bots are using. Summarization not only reduces token utilization, but it also improves the signal:noise ratio in your context window. Chat bots just feel a lot smarter when you summarize the message history.
More or less any off-the-shelf text summarization prompt will do the trick here, although you may want to tweak it to
Use stop sequences and max_tokens
This is pretty standard advice for anyone building on top of GPT, but it seems like a lot of people miss these ones. The max_tokens option lets you set a hard token limit on GPT’s response, and stop sequences allow you to short circuit the model’s response if it generates a token sequence which matches one of your stop sequences.
Let’s consider some concrete use cases.
Over in AdmitYogi Essays, after we’ve checked that the user’s submitted text actually looks like an essay we perform another round of classification to determine what kind of essay we’re working with. The grading rubric for a “why us?” essay is different than the one used for a “personal statement” essay, and so on.
GPT is actually pretty good at this task. We get a little over 90% accuracy on our test set using GPT with very minimal prompt engineering.
Each essay type is represented by a 2 character code. “Personal statement” is represented by the code PS, as an example.
We clearly don’t want the model to generate multiple paragraphs when all we’re after are those codes. Due to this, we set max_tokens to 1 as all of our expected codes are only one token.
const res = await openai.chat.completions.create({
model: 'gpt-3.5-turbo-0613',
messages: [/* ... */],
max_tokens: 1,
});If the model goes rogue and tries generating prose, then the whole thing short circuits because it will instantly exceed that 1 token cap.
Now for an example of stop sequences. In that same AdmitYogi Essays product we have a prompt which generates “though-provoking questions” when the submitted essay is confused and lacks a central theme. The theory is that if the student reflects on these questions they’ll be able to refine their essay and hone in on a unifying central theme.
We only want to generate two of these questions. No more, no less. GPT is usually good at following instructions here, but sometimes things can go haywire [^1 Elsewhere we use GPT to tag recording files based on the content of their transcripts. The prompt responsible for this explicitly asks twice for only up to three tags. It took less than a day for us to see a recording get 17 tags applied.] Stop sequences offer some security against this.
We generate our questions as a numeric list, which means that we have a pretty obvious sequence to short circuit on. If GPT generates the text 3. then that means it’s trying to generate a third question, so we simply set an appropriate stop sequence:
const res = await openai.chat.completions.create({
model: 'gpt-3.5-turbo-0613',
messages: [/* ... */],
stop: ['3.'],
});Lists are one of the more obvious use cases for stop sequences, but there are many other applications for them as well:
- Chat applications. If you only ever want one line responses from GPT, then set
\nas a stop sequence. - Limit to 1 paragraph. Following on from the chat example, setting
\n\nas a stop sequence is a really good way to limit the model’s response to only one paragraph. - Avoiding boilerplate. It’s frustrating to end up with a response that begins with “As an AI model.” Setting that as a stop sequence means you get to bail out early and retry faster, instead of burning tokens.
Leverage “guidance acceleration”
Microsoft have published a Python library named guidance which allows you to perform “guidance acceleration.” This is a fancy way of saying “getting the LLM to fill in the blanks.”
In my post about JSON mode I generated book recommendations according to the following schema and bemoaned the resulting excessive use of tokens.
{
"title": "string",
"author": "string",
"isbn": "string"
}I used a lot of tokens for two reasons. First, JSON is a poor format for GPT that often results in higher token usage compared to alternatives like YAML. Secondly—and, actually, more importantly—I’m asking the model to generate the entire JSON object.
If you reflect on that for a little bit you’ll realize that that’s quite wasteful. I know what structure my desired JSON object should have, and all I really need GPT to do is fill in the blanks for me. That’s what guidance is. Instead of asking GPT to generate the entire JSON object, you instead get the title, author, and isbn values generated on separate lines like so:
The Great Gatsby
F. Scott Fitzgerald
9780333791035And then substitute these values into your expected structure. Microsoft’s library makes this pretty easy to do with minimal code, but it’s not impossible to write your own implementation of this in whatever language you are working with.
Guidance acceleration can have a huge impact on your generated token count if you are generating responses with a static schema like our book. In my last post I noted that minification of the JSON response took it down from 33 to 26 tokens. The guidance acceleration response is only 15.
Realistically it’s not going to do much for your rate limits as prompt tokens typically dominate the completion tokens—but it will have a big impact on generation time, and consequently the user experience!
Anything else?
This is a compendium of strategies that I’m personally aware of and have used, but there might be others I don’t know about.
If you have any suggestions for other strategies that could be added to this post, feel free to send me an email with the details.