OpenAI’s strange 502s
I've been leading the development of a new feature at Crimson Education that we just launched today. Our "Student Center" application is the source of truth for all things related to a student's college candidacy, and the basic unit of storage inside Student Center is a "mission." A mission represents things like extracurricular activities, examinations, internships, and more. It's kind of like a "to do" item in a task tracking app, but missions contain a lot more data than just a title and description.
Research and manual data entry into Student Center are huge time sinks for Crimson staff, so I've been working on incrementally building recommender systems for each section of the Student Center which takes in a student's profile, combines it with our in-house strategy guidelines, and spits out a highly relevant and personalized mission for that student.
The long-term vision was to add a button which would orchestrate all of these individual recommenders together in order to generate a student's entire high school strategy with one click. Today we finally released the first iteration of this, but in order to get it out the door we had to investigate a really strange issue with the OpenAI chat completion API endpoint: about one third of the time, our strategy recommendations would take upwards of 11 minutes to finish generating!
If we dig into the issue by looking at our Datadog APM traces, the root cause of this issue immediately becomes apparent:
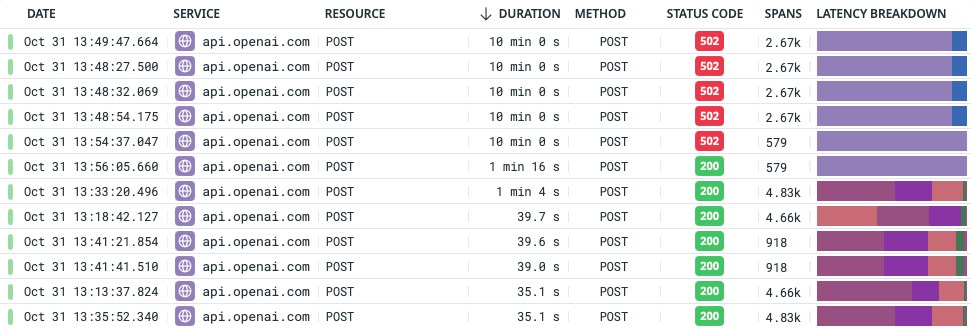
Some proportion of the time—0.28% for us at Crimson, over the past 15 days—OpenAI's chat completion endpoint will hang indefinitely, and you'll only get a response back after their reverse proxy times out at 10 minutes.
This problem with OpenAI hasn't caused us much grief up until now as individual features don't tend to send off too many prompts. But strategy recommendations are a different beast. A relatively "good" strategy generation that doesn't require too much reprompting will send upwards of 140 prompts to GPT, and at that scale a 0.28% individual failure rate results in an overall failure rate of 32.4% across the entire pipeline. Small percentages start to matter pretty early on, which is why keeping an eye on your p95 and p99 latency metrics is so critical in a microservices architecture.
Fortunately, the fix here is simple. Our slowest prompt over the past 15 days took 74 seconds to return a response, so we've simply applied a 2 minute timeout to OpenAI responses going forward. In addition to this, we've set a (generous) 15 second connection timeout. In situations where we end up triggering that 2 minute timeout we fall back to our pre-existing retry logic, and will generally manage to get a response to the retried API call in a timely manner.
Admittedly, triggering that timeout results in a degraded user experience. Thanks to some performance improvements on our end, our best case scenario for generating strategy recommendations end-to-end is about 26 seconds. Reprompts and retries will usually push this time up to about 90 seconds. Waiting a whole two minutes pushes things out significantly compared to these benchmarks, so we'll be looking to finetune things over the coming weeks. In any event, we're far better off now compared to when we'd spin our wheels for 10 minutes.
A 10 minute timeout on a reverse proxy is unusually long—the default timeout for nginx is only 60 seconds. This unusually high timeout is what makes this issue particularly interesting, but it makes sense within the context of OpenAI. Our slowest-running prompt generates about 1k tokens using the gpt-3.5-turbo model which barely scratches the surface of what's possible with GPT. Generating really long documents using gpt-4-32k could easily require a 10 minute timeout.
But for our use case—and likely for your use case, too—we're never going to send out an individual prompt which takes 8 minutes to generate a response for. Even if we did down the line, we can configure timeouts on a per-request basis anyway.
If you're using OpenAI's chat models, then you really ought to benchmark the performance of your prompts and set a timeout accordingly. That 0.28% failure chance will get you otherwise.