Leveraging logprobs to build better generative AI systems
Autofilling form fields has become an increasingly common and practical application of generative AI. With just a bit of context and a well-crafted prompt, AI can produce reliable results for various input fields. One of the most appealing aspects of this use case is its simplicity and quick implementation—developers can often build and deploy this feature without extensive training data, sometimes in just a few hours.
Form field autofilling was one of the first things I ever built with GPT, and since then it’s been infectious throughout applications I’ve maintained. It’s a really great feature to pitch if your exec wants to munge AI into your product, because it genuinely helps users save time while also requiring little investment. It’s unlikely you’ll need to embark on a dramatic data project to successfully ship it, and retrofitting a “✨” button on your form field to trigger it is usually straightforward.
In this post we’ll take a look at a very simple prompt for categorizing extracurricular activities like “chess club” or “soup kitchen,” based on their title. We’ll then take a look at a case where our simple prompt gives us weird output, and explore some metrics we can use to help our system monitor itself in production. By the end you’ll understand two common metrics for evaluating an LLM’s confidence in its output, and have a concrete idea of how to use these metrics to build more reliable user-facing genAI systems.
The prompt
The prompt itself is very simple. There are some alternate designs you could use, but in my experience a zero-shot prompt like this one works well enough for most use cases:
Given the name of an extracurricular, categorize it according to the following taxonomy:
* Academic
* Arts
* Business
* Environmental
* Media
* Sports
* Technology
* Volunteer
Return the category only with no further explanation.
Extracurricular: Soup kitchenThe response to this prompt is Volunteering as we would expect, but this is only a single example. How can we have confidence that our prompt will perform well in the real world?
One option is to build an evaluation suite. We’d dream up a hundred or so extracurriculars—GPT itself is great for generating options—and then manually label them with our expected categorization. Tools like promptfoo can be used to run your prompt against the evaluations you’ve built and it’ll spit out information about how accurately your prompt handles your examples.
In future I’ll write a more in depth post about LLM evals, but for now we’ll test our prompt interactively by manually keying in different extracurriculars. Although somewhat labor intensive this is by far the easiest way to evaluate a prompt, and most people are familiar with it.
Let’s try “StarCraft 2.” Given the taxonomy I’ve defined I would expect StarCraft 2 to categorize as a sport, but GPT thinks otherwise:
Given the name of an extracurricular, categorize it according to the following taxonomy:
* Academic
* Arts
* Business
* Environmental
* Media
* Sports
* Technology
* Volunteer
Return the category only with no further explanation.
Extracurricular: StarCraft 2Once you already know about an edge case like this you can prompt engineer or fine-tune your way out of it, but how are you supposed to account for unknown unknowns? End users can type anything as an extracurricular title. Even if we were to test a couple hundred specimens, we'd barely make a dent in the total number of possible inputs. This problem is one of the most common failure modes for systems built on top of LLMs
At some point you need to be able to automatically monitor the quality of your prompt outputs. There are a couple of l
Measures of confidence
Logprobs
Probabilistic models like Naive Bayes typically output a probability or confidence metric in addition to their prediction. Confidence scores are really useful, because you can use them to identify potentially problematic outputs at runtime.
The GPT models don’t output confidence scores by default, but you can opt in to receiving them by setting the logprobs option to true:
const result = await openai.chat.completions.create({
logprobs: true,
messages: [/* ... */],
model: 'gpt-4o-mini-2024-07-18',
temperature: 0,
});{
// ...
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Volunteer",
"refusal": null
},
"logprobs": {
"content": [
{
"token": "Volunteer",
"logprob": -0.000004365741,
"bytes": [
86,
111,
108,
117,
110,
116,
101,
101,
114
],
"top_logprobs": []
}
],
"refusal": null
},
"finish_reason": "stop"
}
]
}When this flag is set, you’ll receive a new logprobs field on each generation in the choices array. “Logprob” is a portmanteau of the words “logarithmic probability.” The numeric value you see for logprob is simply the natural logarithm of the original probability.
Logprobs are used for both efficiency and accuracy. The problem with plain probability values is that to compute the overall probability of a token sequence you must multiply the probabilities of each individual token together. This is vulnerable to integer underflow due to precision limitations of floating point numbers. It’s easy to end up in this situation as “natural” probability values range from 0 to 1—so the sequence of multiplication always trends towards zero.
Logarithmic probability values range from 0 to infinity, which solve the underflow problem. Logarithms also have a nice property where log(x * y) = log(x) + log(y), and adding numbers together requires less compute than multiplying them together.
Converting from a logarithmic probability to a probability we can understand as humans is easy. You simply exponentiate e by the logprob. Using the logprob from the “Volunteer” example, we can see that the model is extremely confident in its output:
probability = e ^ logprob
= e ^ -0.000004365741
= 0.9999956343
= ~100%In contrast, the model is a lot less sure about its “Technology” categorization for “StarCraft 2”:
probability = e ^ logprob
= e ^ -0.12650341
= 0.8811711447
= 88.1%If our output spans more than a single token, we’d calculate the overall probability of the output token sequence by summing the logprobs together before exponentiating e. For example, we could ask a different question and then calculate the overall probability of the answer “StarCraft” which spans two tokens. The result for this example is 92.4%:
What is the name of the franchise that has Zerg?
Return the name of the franchise only with no further explanation.{
// ...
"logprobs": {
"content": [
{
"token": "Star",
"logprob": -0.0000021008714,
// ...
},
{
"token": "Craft",
"logprob": -0.07889034,
// ...
}
],
},
// ...
}probability = e ^ (-0.0000021008714 + -0.07889034)
= e ^ -0.07889244087
= 0.9241393187
= 92.4%I find 92.4% confidence a rather surprising result. I think “StarCraft” is the only reasonable answer to the question in the prompt.
One problem with logprobs is that the overall probability of a sequence inevitably trends towards zero. I find that it’s almost never worth using logprobs in this way for sequences longer than a single token. In this “StarCraft” example the initial “Star” token has a ~99.9% probability while the following “Craft” token has a ~92.4% probability. The relatively low probability for the second token explains the low probability of the overall response.
“Craft” feels like a very likely continuation from “Star.” What explains the ~8% uncertainty?
The logprobs option only returns the logprobs for the response tokens which the model actually selected for its final response, which limits our ability to debug. But we can dig a bit deeper by also passing the top_logprobs option as part of our API request, which will make GPT return the top N alternate completion tokens it didn’t pick. When we do this, the reason for the big drop off between “Star” and “Craft” becomes obvious—GPT thinks there’s a 6% chance of “craft” following “Star”.
{
"token": "Craft",
"logprob": -0.07889034,
"bytes": [...],
"top_logprobs": [
{
"token": "Craft",
"logprob": -0.07889034,
"bytes": [...]
},
{
"token": "craft",
"logprob": -2.5788903,
"bytes": [...]
},
{
"token": " Craft",
"logprob": -14.453891,
"bytes": [...]
},
{
"token": "CRA",
"logprob": -17.57889,
"bytes": [...]
}
]
}The logprobs option only returns the logprobs for the response tokens which the model actually selected for its final response. We can dig a bit deeper by also passing the top_logprobs option as part of our API request, which will make GPT return the top N alternate completion tokens it didn’t pick. When we do this, the reason for the big drop off between “Star” and “Craft” becomes obvious—GPT thinks there’s a 6% chance of “craft” following “Star”.
If we consider top_logprobs and don’t care about case sensitivity, our revised probability calculation for the “StarCraft” response would then look like the following:
probability = e ^ (-0.0000021008714 + -0.07889034) +
e ^ (-0.0000021008714 + -2.5788903)
= 0.9241393187 +
0.07585797774
= 0.9999972964
= ~100%You could also go a step further and strip whitespace so that the probability for the Craft token gets folded into this calculation, although in this case it doesn’t change the result and in other cases the whitespace could have a meaningful impact on the semantics of the final response.
This solves our problem, but there's actually a much better way of measuring GPT's confidence in longer responses.
Perplexity
A small bit of math lets you compute a metric called "perplexity"—not to be confused with the company—which provides a more comprehensive measure of the model's certainty across all tokens in a response.
Perplexity is particularly useful for evaluating the model's confidence in multi-token outputs, where individual token probabilities might not tell the whole story.
Perplexity is straightforward to calculate from logprobs:
const response = await openai.chat.completions.create({
// ...
logprobs: true,
});
const logprobsContent = response.choices[0].logprobs.content;
let logprobsSum = 0;
for (const it of logprobsContent) {
logprobsSum += it.logprob;
}
const perplexity = Math.exp(-logprobsSum / logprobsContent.length);
// => 1.0402345540195412The perplexity metric tells us roughly how many equally likely options the model had at each point in its response.
A perplexity value of 1 means that the model only predicted a single sequence of tokens the whole way through its response, and indicates the model has perfect confidence in its response.
Higher perplexity values indicate that the model had to pick between more possible tokens throughout its response, which means the model is less sure about its output.
Our “StarCraft” answer has a perplexity value of 1.04, which indicates high model confidence.
My experience is that logprobs are very useful if you’re working with responses that are one token long (e.g. classification prompts that expect a “yes” or “no” response) or when you otherwise only care about the model’s confidence in the first output token. They tend to be less useful when evaluating multitoken responses, and I always reach for perplexity instead for those use cases.
Using logprobs for better user experiences
Armed with these metrics, it’s straightforward to come up with techniques for dealing with low confidence LLM predictions. The process looks like this:
- Decide which metric(s) you want to use.
- Note that there are more evaluation methods out there than just logprobs and perplexity.
- Determine thresholds for each metric.
- A quick and easy way to do this is to compute your chosen metrics for a few examples. This will give you a good ballpark for where to set your threshold.
- For a simple and direct classification task like this, strict thresholds work well. Something like 95% first-token probability or 1.05 perplexity might be reasonable.
- Intervene when an LLM response violates your chosen threshold.
- Store the final input/output pair for finetuning or model distillation down the line (optional).
There are many different ways we could choose to intervene. The two most straightforward options for our extracurricular categorizer are:
- Ask the user for more information (”What did this extracurricular involve?”) and then reprompt the LLM, using the extra information as part of the prompt.
- Style the autofilled field in a way that communicates uncertainty.
- Use
top_logprobsto retrieve the top N possible categorizations, and have the user explicitly select the category they prefer.
The first option is deceptively simple; there are many use cases where the LLM will still struggle to produce a high-confidence output even with extra context. This path usually involves a lot of prompt engineering, which you are generally better off investing in your original categorization prompt.
The second option also has some challenges. At a past job we experimented with highlighting fields orange when the LLM produced a low-confidence result, but it was hard to teach users what the orange highlight meant. We didn’t have much space on the form to include affordances, and because we initially only added this functionality to a single form it was hard for onboarding instructions to stick. If you’re deploying LLM autocompletion to every form in your app or are building a greenfield project where you can make this a prominent part of the onboarding experience, then this is a much more realistic approach to the problem.
The last option is by far the most simple, and also tends to be the most effective. There’s no potential for hallucination as the user is in direct control over the final output, and the choices are restricted to only options that are valid categories.
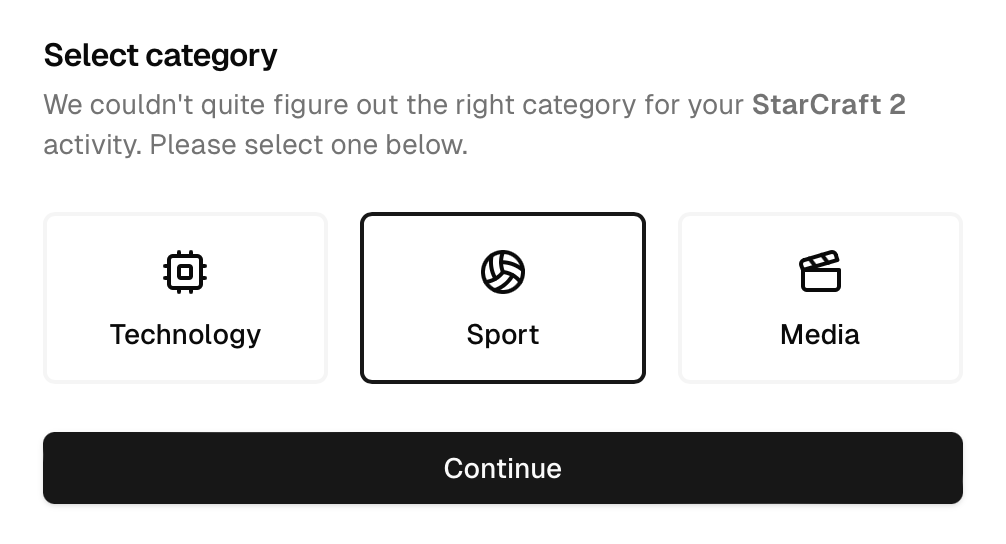
Regardless of the specific intervention you choose to implement, the last step in the process is to optionally store input/output pairs somewhere. Popping up a dialog and prompting the user to disambiguate the categorization solves the problem for them in the moment, but the next person who tries entering “StarCraft 2” will end up running into the same problem.
If you collect input/output pairs as your users issue corrections, then over time you’ll build up a sizable dataset of training pairs. Some mix of RAG, fine-tuning, and model distillation can be employed to get recurring value from that dataset and reduce the likelihood you need to prompt the user for guidance in the first place. Getting the answer right from the start is a much better user experience.
Actually consuming that dataset is theoretically easy, but depending on your use case there may be additional considerations to keep in mind. Due to the nature of our business we never really needed to worry too much about data poisoning attacks at Crimson, but if you’re selling a mass market B2C app then the calculus will be different. Covering the details of how to go about using your data in a safe and controller manner is out of scope for this post, but I’ll write more on this down the line.
Limitations
As with anything related to generative AI, there are limitations to the metrics we’ve discussed. Generative AI is an inherently unreliable and probabilistic technology, and it’s hard to build totally reliable systems on such an unstable foundation.
Model support
As I’ve written previously, capabilities differ between LLMs. While logprobs are a tremendously useful feature for many different use cases, they are unfortunately not available from certain language models—Anthropic being the big one.
Because Anthropic’s API does not expose token logprobs, the techniques covered in this post are not usable if you are using their Claude models for inference. I generally recommend building your application against at least two different LLMs for redundancy and performance; a Mistral model is a better backup than an Anthropic model for use cases where you want access to token logprobs.
Logprob variance
The logprobs you see for a response can vary from one request to another, and the range can be surprisingly high. I ran the categorization prompt at the start of this post 100 times on “StarCraft 2” and “Soup kitchen,” and have compiled the results below. I used temperature = 0.7 with no preset seed for this experiment.
| Activity | Categorization | Count | Mean | SD |
|---|---|---|---|---|
| StarCraft 2 | Technology | 91 | 86.0% | 5.9% |
| Media | 8 | 13.1% | 6.2% | |
| Gaming | 1 | 1.8% | — | |
| Soup kitchen | Volunteer | 100 | 100.0% | 0.0% |
There are three key things to note from this little experiment:
- An out-of-band “Gaming” categorization crept into the results. LLMs go off script surprisingly often, and this is even true for very simple prompts. You can never trust raw LLM outputs and should always validate (in this case, by ensuring the output text is truly a valid member of our enum).
- As confidence goes up, logprob variance decreases. The “Soup kitchen” → “Volunteer” categorization is rock solid, whereas the error bars for the “StarCraft 2” categorizations are substantial.
- Because logprobs can vary from one API call to another, it’s possible for some inputs to end up on either side of your metric’s threshold. You want to be mindful of this when assembling input/output pairs—it means marginal inputs will end up with fewer human-provided training examples in your dataset.
Confidence vs accuracy
Related to the above, it’s important to remember that confidence doesn’t always mean the same thing as accuracy. It’s possible for a model to be simultaneously confident and wrong in its response—just like a human can be. Benchmarking and evaluating LLMs is notoriously difficult, even for relatively simple problems like an extracurricular categorizer.
In particular, model bias can be a real problem. There are many cases where machine learning models produce biased outputs even without malicious intent on the part of the engineer(s) that trained it. Models disproportionately rejecting mortgage applications is a well-documented phenomenon.
In my experience there is usually a good correlation between confidence and accuracy, but you need to benchmark this yourself to validate it on your specific use case. There is no substitute for building an eval suite, running it, and then graphing your confidence metrics vs accuracy. The stronger the correlation you observe, the more useful the techniques in this article will be for you.
It’s also worth going one layer deeper and reasoning about the consequences of your model giving out the wrong answer. Our extracurricular categorizer is likely harmless, but decisions on mortgage applications, health insurance claims, or criminal justice proceedings could have significant and long-lasting impacts on individuals’ lives. If you are working in such a high-stakes scenario, you should ask yourself whether it’s truly appropriate to outsource decision making to an LLM.
Conclusion
Leveraging logprobs and perplexity metrics can significantly enhance the user experience when working with generative AI systems. By setting appropriate thresholds and intervening when necessary, it’s possible to create far more reliable and user-friendly applications. Collecting a corpus of input/output pairs also opens up the possibility of cost and latency savings down the line by training your own smaller, more efficient models.
While these techniques have limitations—like anything else in the generative AI space—they provide valuable tools for managing LLM outputs and improving overall system performance.