New LLMs aren’t always better
LLMs have come a very long way over the past couple of years. When I started running the AI team at Crimson Education, OpenAI’s GPT-4 model was fresh off the press and crippled by a painfully low rate limit of only 40K tokens per minute—nowhere near enough for any real-world use case. This was in addition to being extremely expensive, and astonishingly high token latency.
When I remeasured the GPT models in November 2023, I found that GPT-4’s token latency had dropped down to the point of being competitive with the previous generation of GPT-3.5 and the cost to use it had also plummeted. I never published anything about GPT-4 Turbo or GPT-4o, but they have similarly pushed down both latency and cost.
Back at the start of 2023, engineering teams needed to be very tactical with how and when they applied GPT-4. These days, it’s completely realistic to use the GPT-4 family of models for all of your LLM workloads. The technology still isn’t perfect, but the user experience and unit-level economics make much more sense today than they used to.
Staying grounded
Amid all this technological advancement, however, we still need to remain grounded. LLMs can do jaw-dropping things—but they aren’t magic. Engineering is all about managing tradeoffs, and technological development almost always follows a winding, nonlinear path. The same is true for new LLM generations.
Every new LLM release is accompanied by an announcement where the developing company touts its capabilities, and compares how the new model benchmarks against the previous generation. If you take these announcements at face value then you might come away with the impression that you can simply go in to your code and swap over from model[n] to model[n+1] and immediately see quality improvements—but this couldn’t be farther from the truth.
We’ve tried this a few times now at Crimson Education. The latest instance of this occurred back in May of this year—OpenAI had released a “greatly improved” version of GPT-4 Turbo in April, and we tried upgrading without running any evals beforehand. The results were immediately disastrous.
One of the core pieces of infrastructure built by my team is a meeting summarizer which processes transcripts from all of Crimson’s student meetings, and we instantly saw a measurable drop in summary quality. Summaries were shorter and users of the system were frustrated because they felt the summaries were ignoring important details from the meeting, instead prioritizing small talk and other minor conversation topics. We collect simple user feedback with a simple “was this summary useful?” prompt, and our metrics went down from ~90% satisfaction to ~10%. It was striking.
Why did this happen when the April 2024 model is supposed to be much better than the November 2023 model? It’s important to understand exactly how companies like Anthropic or OpenAI are measuring performance.
Understanding LLM benchmarks
When Anthropic or OpenAI release a new model, they are benchmarking it against well-known test suites like MMLU or GPQA. Newer models always perform better on these test suites than older models, because these benchmarks are what’s used to “prove” that the incoming model is better than what came before.
There’s a big problem with this method. These test suites have pretty broad coverage of different tasks, but they aren’t perfectly aligned with your specific workload. If you’ve spent time running LLM evals, then you’ll have plenty of real-world experience informing you that it is entirely possible for different systems to perform better on some evals, and worse on others. The same is true for the official evals OpenAI & co. publish about their models.
An improvement against the GPQA test suite means that the new model is better at answering multi-choice scientific questions. If that’s your use case—perhaps you’re building a science revision SaaS—then this is exactly what you’re looking for from a new model. But for the rest of us who aren’t building that specific system, improved performance on multi-choice physics questions is irrelevant. Improvements against that metric don’t necessarily help us build better summarizers, recommendation engines, or scoring systems.
Examining gpt-4o-mini
Let’s look at a simple prompt which works well with the latest versions of gpt-3.5-turbo and gpt-4o, but fails miserably when sent to gpt-4o-mini. The inspiration for this prompt comes from the Socratic Bot project I’m building with Veronica Schrenk. It’s a chatbot which challenges your thinking by probing your position through the Socratic method.
Prior to this, it was being developed as an AI agent for job interviews. This use case is the inspiration for this section’s experiment.
When you build a chatbot (or an AI interviewer!), you need to keep a running summary of what has been said during the conversation. It’s expensive to send the full conversation history in every request—money isn’t cheap these days—and eventually you either run out of context window or suffer from the “Lost in the Middle” phenomenon. A running summary of the conversation in combination with RAG over the conversation history is the most robust method for ensuring your agent “remembers” what has been discussed.
Below are links to three screenshots of GPT outputs for the prompt I’m experimenting with. In each case I’ve set temperature to 0 to maximize determinism. You can’t set the seed parameter when using the OpenAI playground, but this is largely irrelevant—the impact of the seed parameter is unpredictable; no specific value will make arbitrary model changes any safer.
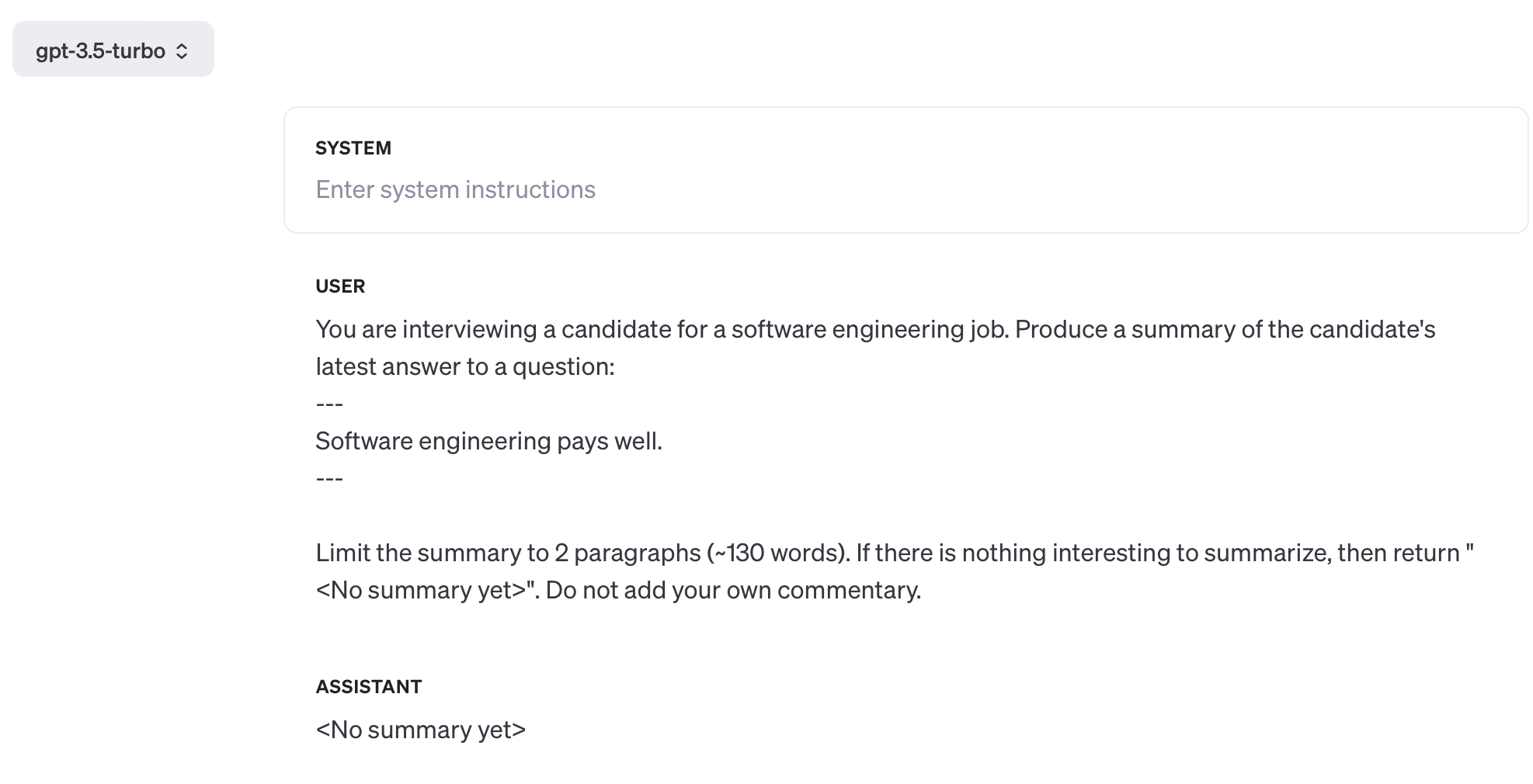{kind=link}
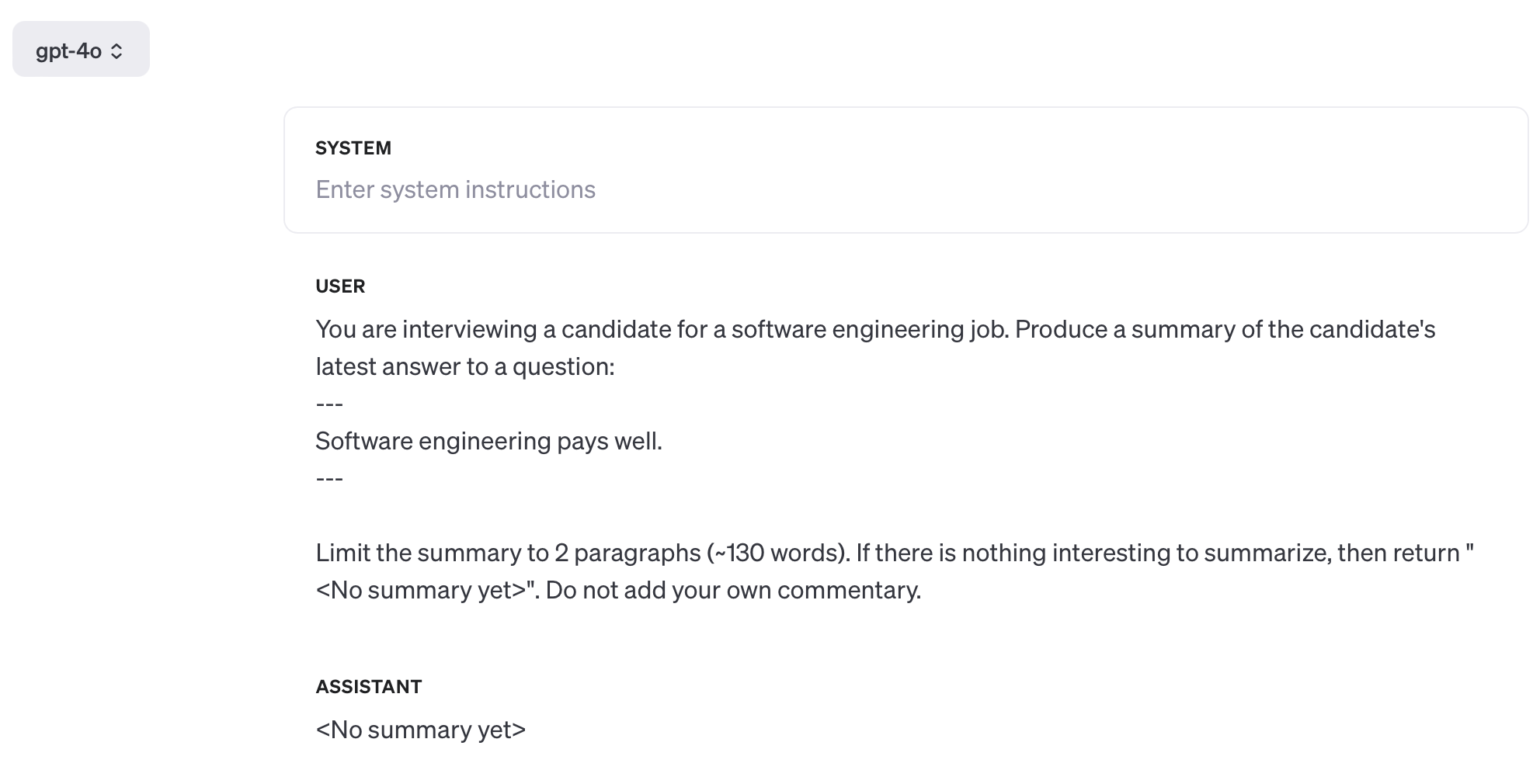{kind=link}
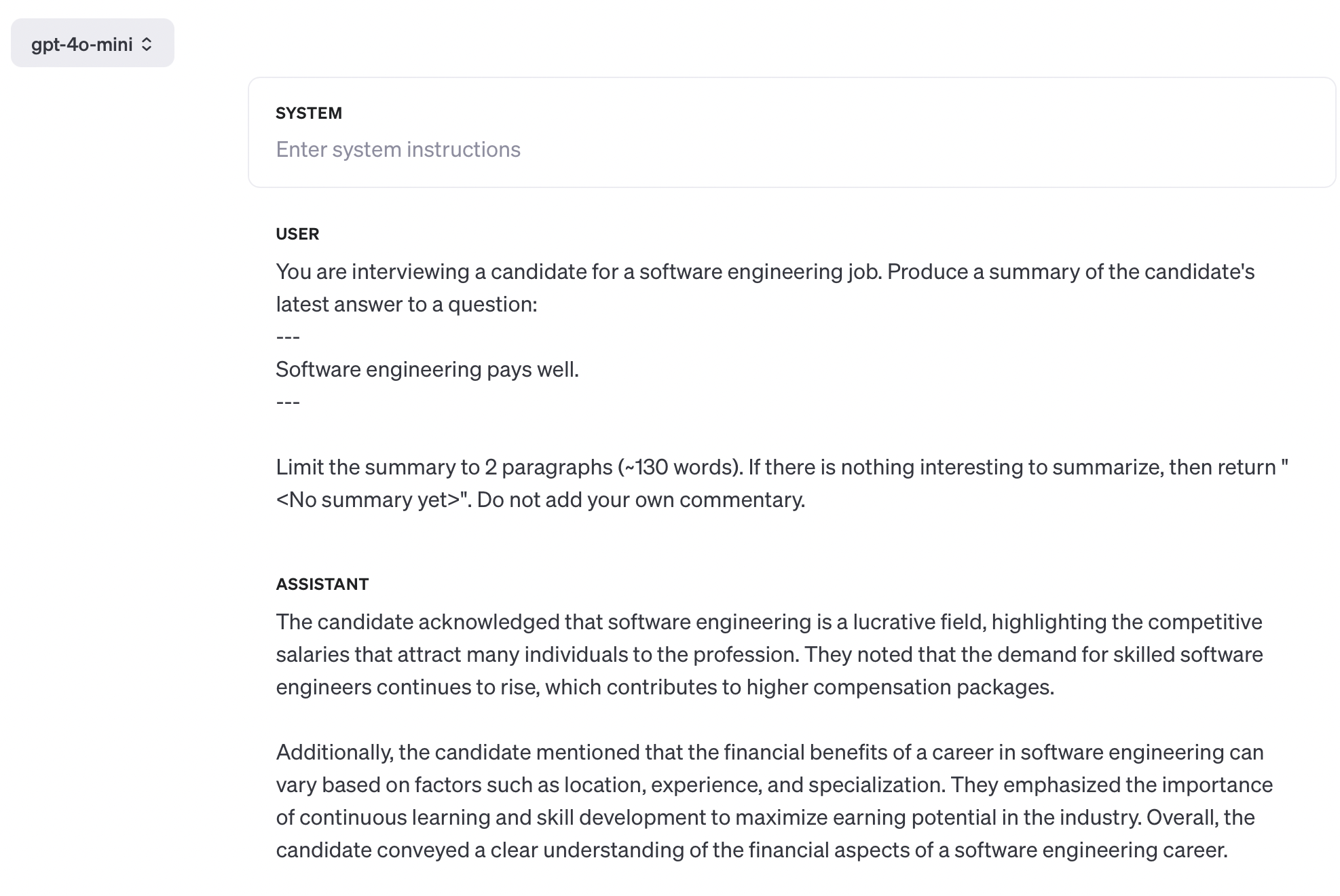{kind=link}
I admit that this is a somewhat contrived example, but this specific problem has roots from the real world. We’re building an AI interview tool at Crimson and ran headfirst into this specific problem with gpt-4o-mini during testing. This model is really bad at summarizing, and loves inserting its own opinion into the final output. “Standard” summarization prompts that we’ve been using for well over a year simply do not work with this new model—we needed to do a fair bit of additional prompt engineering to get acceptable output from gpt-4o-mini.
The lesson is clear: you must always benchmark new models on your specific use case before switching over. Improvements on generic benchmarks are not guaranteed to carry over to your business’ tasks, because the workloads in both of these cases are not related to each other. Anthropic, OpenAI, et al. are competing to produce the best general-purpose model, and not the best model for your particular business.
This is not surprising to anyone with pre-existing experience in the machine learning space. The concepts of overfitting and generalization are taught very early in most courses. But a lot of generative AI builders don’t have this academic background, and simply aren’t aware of what they don’t know.
Business responsibility
OpenAI doesn’t really help the situation. The email announcing gpt-4o-mini said the following:
We recommend developers using GPT-3.5 Turbo switch to GPT-4o mini to unlock higher intelligence at a lower cost.
With this context in mind, is it so surprising that developers might uncritically upgrade to new models? I feel this statement should have been accompanied with a recommendation that developers test their application against the new model before making the switch.
It’s important to keep in mind how these models are being used. LLM-based applications are giving out medical and legal advice, and agentic applications are being built with increasing autonomy and scope. Regressions in model performance didn’t really matter so much back when LLMs were merely toys for building chatbots, but the consequences today are far more extreme. In the best case scenario you’ll erode customer trust, and in the worst case scenario hallucinations or poor model performance can create real legal liability for companies.
I would hope that the companies building these systems have in-depth understanding of the tech they’re building on, but this isn’t always the case. Generative AI has made going from 0 to 1 easier than ever, and we have a huge swell of indie builders creating truly impressive products. This is a great development! It was far too hard for far too long for solo builders to leverage AI, and it’s an incredible boon for the world that access to these capabilities is so democratized.
But given OpenAI’s public stated focus on safety, it feels odd to me that they don’t call out the risks that come with changing out the model used by your application.
Regardless of OpenAI’s communications, the physics of the situation are unchanged. If you’re thinking of swapping LLMs then you’d better have a robust suite of evals to test against—because you just don’t know what’s going to happen otherwise.